Field notes
Writing on scraping,
data, and building on APIs.
Tutorials, playbooks, and field notes from building one of the most complete social APIs on the market.
Latest post
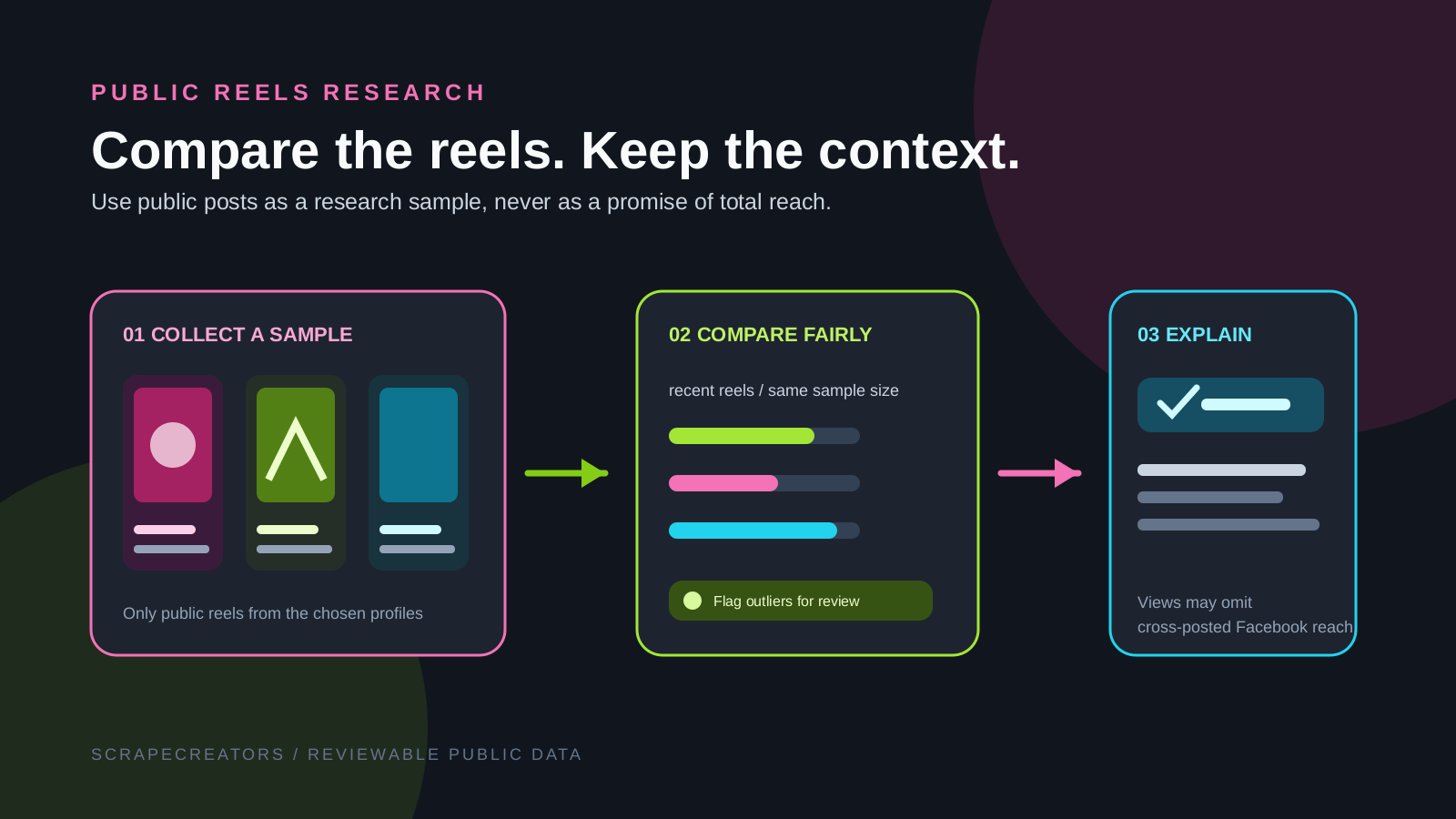
Research Public Instagram Reels With an AI Skill
A copyable AI skill for comparing public Instagram Reels from selected profiles, pulling post context where needed, and reporting the limits behind play-count comparisons.
All posts
75 total
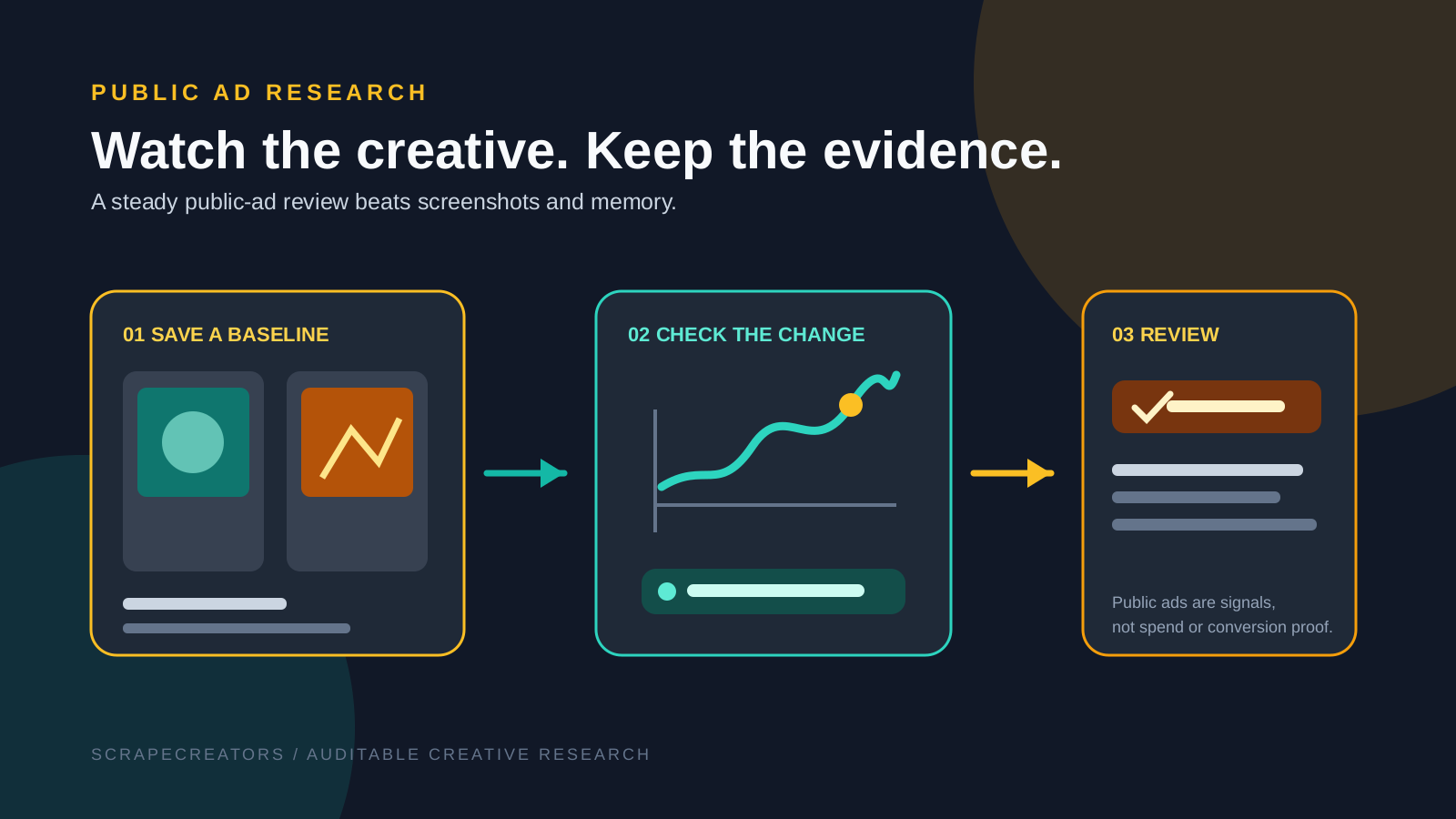
Monitor Meta Ad Library Creative With an AI Skill
A copyable AI skill for monitoring public Meta Ad Library creative. Save a baseline, compare visible changes, and return source URLs and caveats instead of overclaiming ad performance.
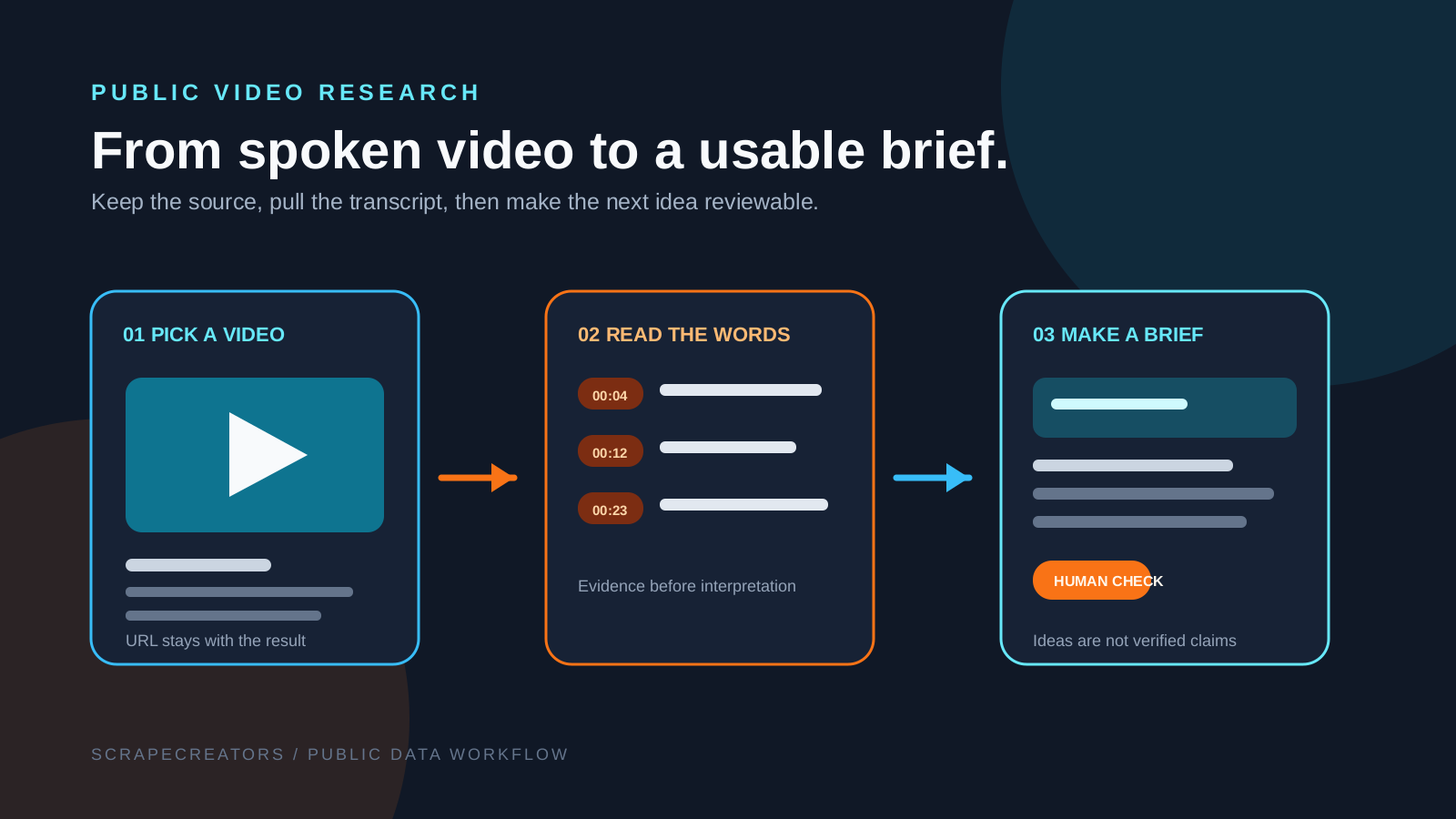
Turn TikTok Transcripts Into Content Briefs With an AI Skill
A copyable AI skill that turns public TikTok transcripts into an auditable content brief: source URLs, hooks, themes, evidence, and ideas that still need human review.
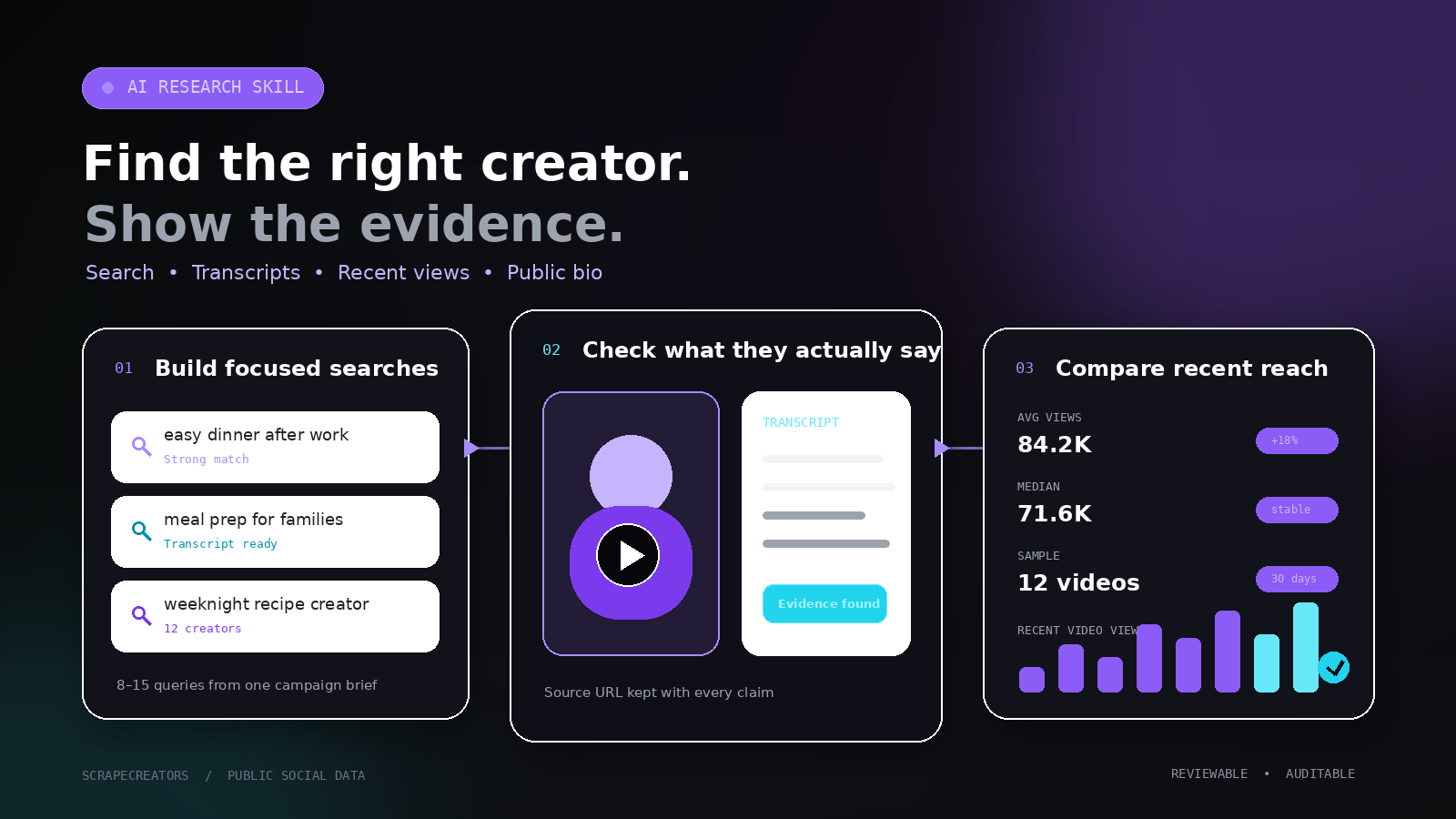
How to build a TikTok creator research skill with AI
Use an AI skill to turn a niche and customer into TikTok searches, analyze what creators say, calculate recent average views, and collect only business emails they publish in public bios.

How to Write Instagram Reel Hooks From Transcripts
I stopped guessing at hooks. I scraped a creator's top Reels, saved the transcripts, and turned first lines into a hook bank I can open in Cursor.

Best Social Media APIs for Developers in 2026: 10 Compared
Compare 10 social media APIs for developers by platform coverage, pricing, output, and maintenance. See when a public-data scraping API fits better than an official platform API.

Best Web Scraping APIs in 2026: 10 Tools Tested & Compared
We tested and priced the 10 best web scraping APIs of 2026: Bright Data, Zyte, ScrapingBee, ScraperAPI, Scrape Creators and more. Compare cost per 1k, success rates, and which one fits your project.

Best SERP API in 2026: 10 Tools Tested, Priced & Compared
We tested and priced the 10 best SERP APIs of 2026: SerpApi, Serper, ScraperAPI, DataForSEO, Scrape Creators and more. Compare cost per 1k, speed, free trials, and which one fits your project.

How to Download TikTok Videos and Store Them on a CDN
Learn how to programmatically download TikTok videos and store them in cloud CDNs like Supabase, S3, or Cloudinary.

Best Instagram Scraping APIs in 2026: Comparison and Review
Compare the top Instagram scraping APIs of 2026, from public data solutions like Apify and ScrapeCreators to behind-the-login services.
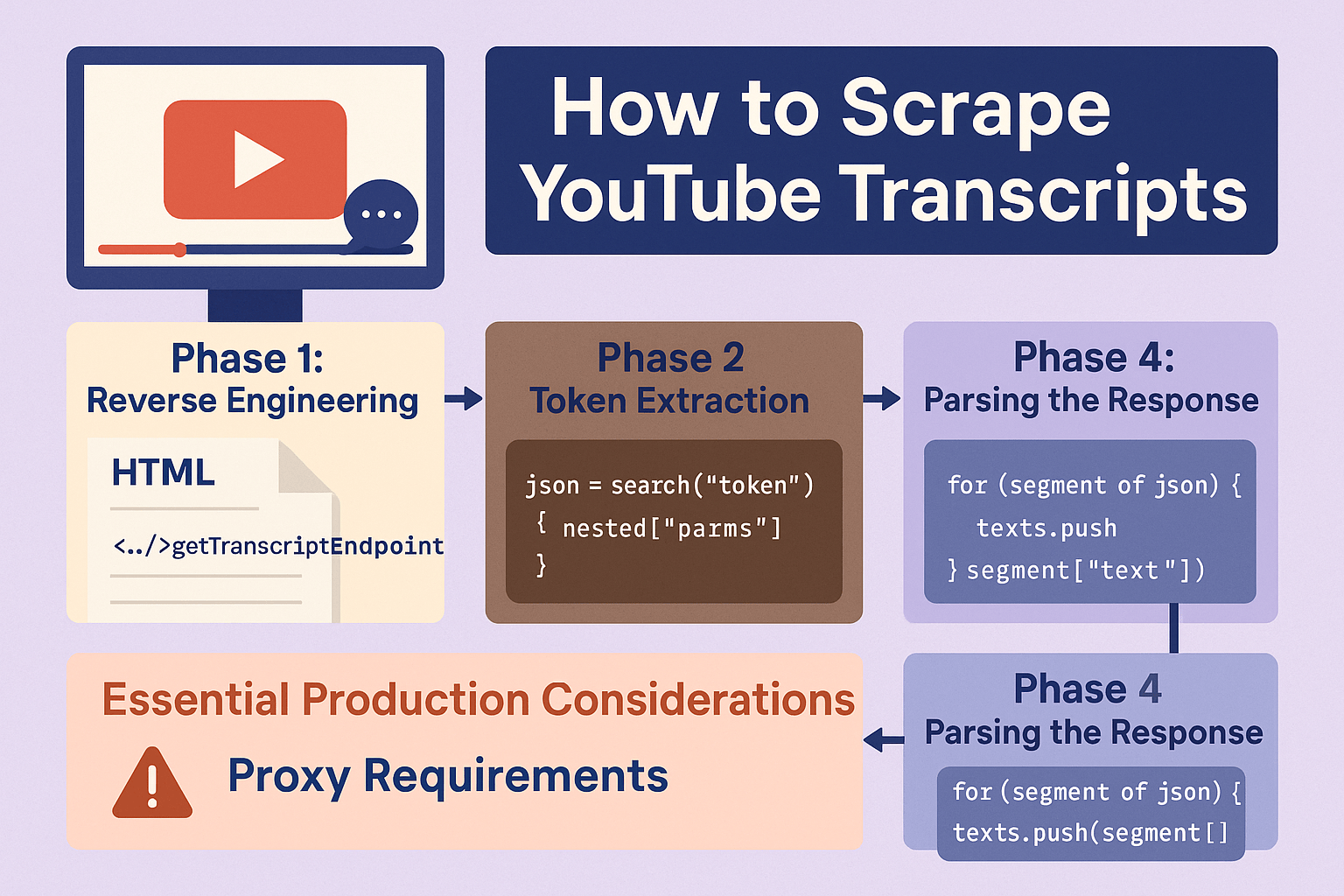
How to Scrape YouTube Video Transcripts: Step-by-Step Developer Guide
Master the art of extracting YouTube video transcripts by reverse-engineering YouTube's internal API.

What Are Social Media Intelligence APIs? How to Use Them
Discover how Scrape Creators API enables rapid social media data extraction across all major platforms.
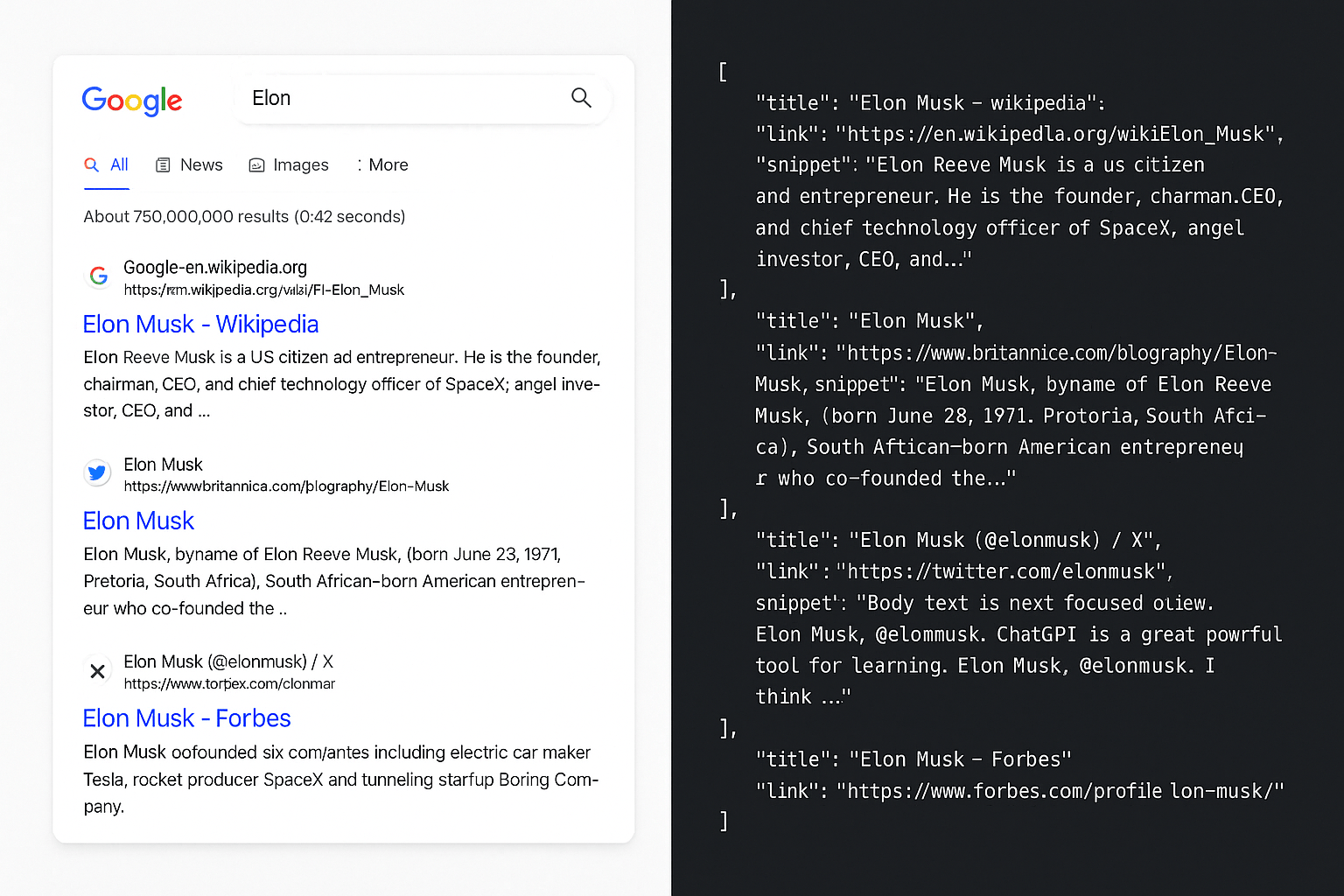
How to Bypass Google's Anti-Scraping Restrictions
Learn how to scrape Google search results using a straightforward approach with the Impit package and custom parsing logic.
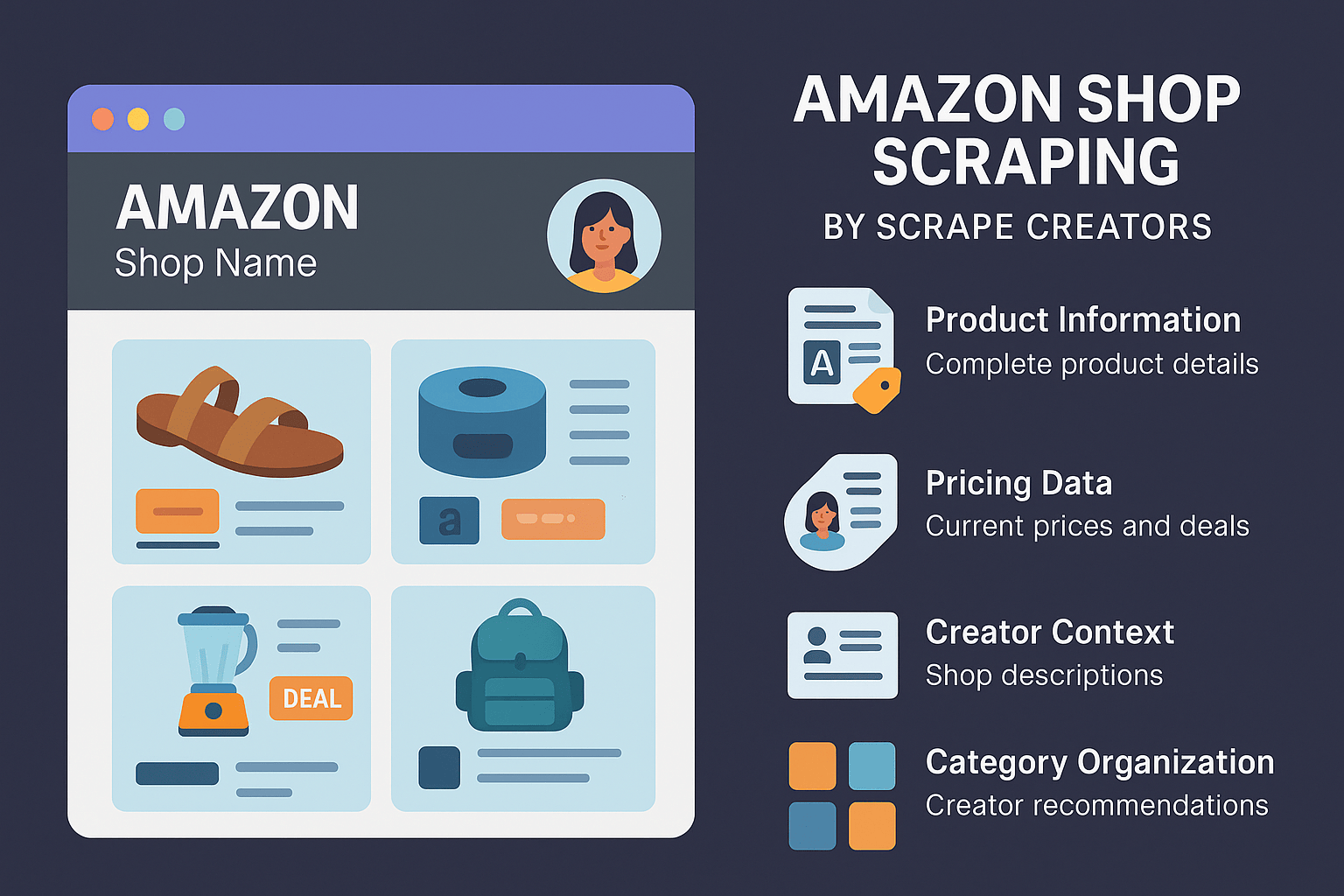
How to Scrape Amazon Creator Shops for Influencer Product Data
Scrape Creators now supports extracting product data from Amazon Creator Shop pages

How to Search Nested JavaScript Objects by Key
Function that searches deeply nested JavaScript objects for specific keys when working with complex API responses and scraped data structures.

What Is Logo.dev? A Simple API for Adding Company Logos
Logo.dev is a simple HTTP API for company logos by domain—the practical successor many teams wanted after Clearbit's logo product changed. Every SaaS dashboard, CRM, and email template still needs crisp brand marks without maintaining your own asset library. I…
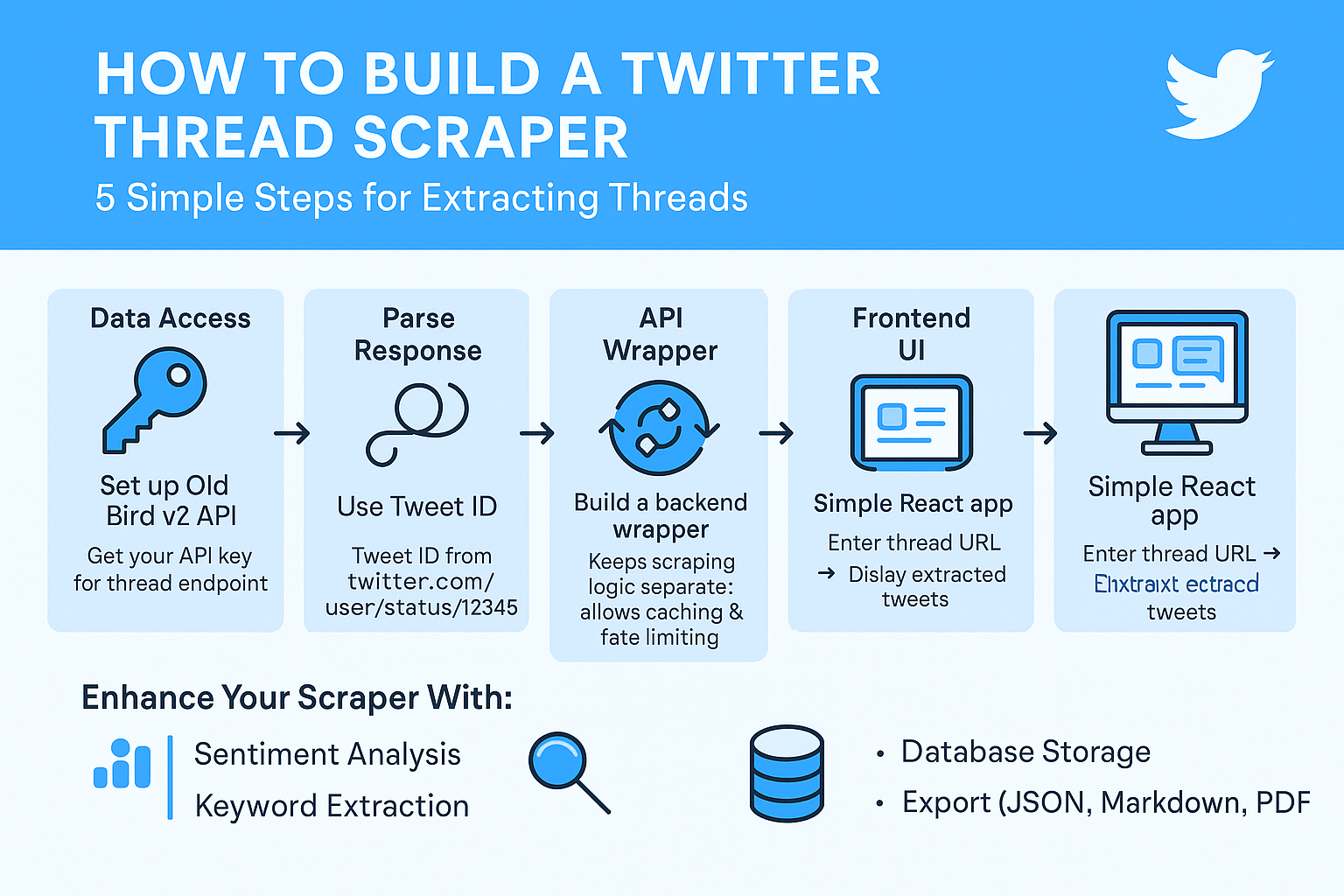
How to Build a Twitter Thread Scraper in 5 Simple Steps
Learn how to build a complete Twitter thread scraper using Old Bird v2 API and AI code generation in just 5 steps.
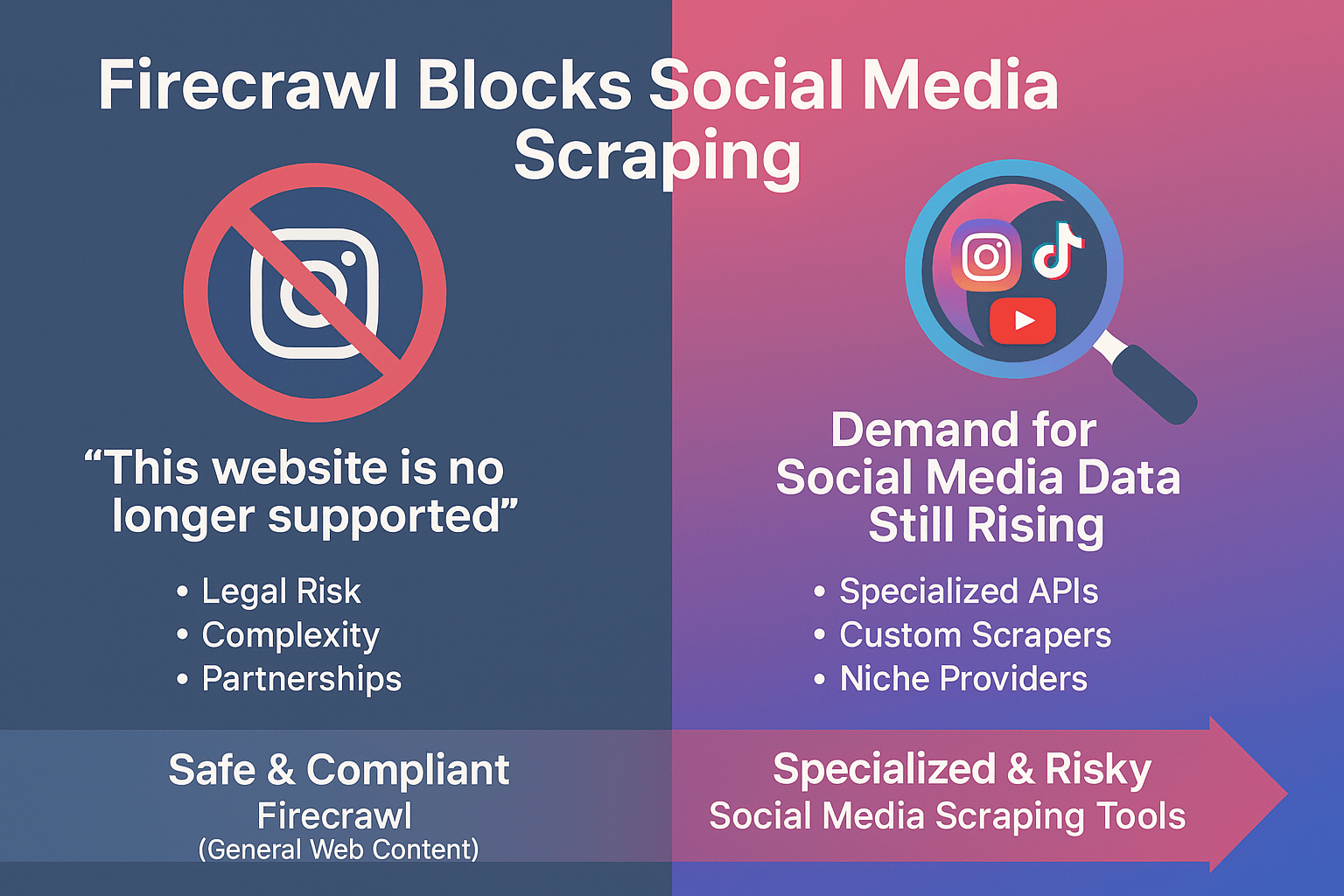
Firecrawl vs Scrape Creators: Which Social Scraping API Should You Use?
Firecrawl actively blocks Instagram, YouTube, and TikTok scraping, creating a significant market gap for social media data extraction services.

How to Scrape All Videos from Any YouTube Channel: A Step-by-Step Guide
Learn how to extract complete video listings from any YouTube channel by reverse-engineering YouTube's internal API endpoints.

How to Extract Facebook Comments from Posts and Reels
Scrape Creators API now supports extracting comments from Facebook posts and reels, opening up new possibilities for social media scrapers.

How to Detect TikTok Shop Products in Creator Videos
Scrape Creators API now identifies specific TikTok Shop products that creators promote in their videos.
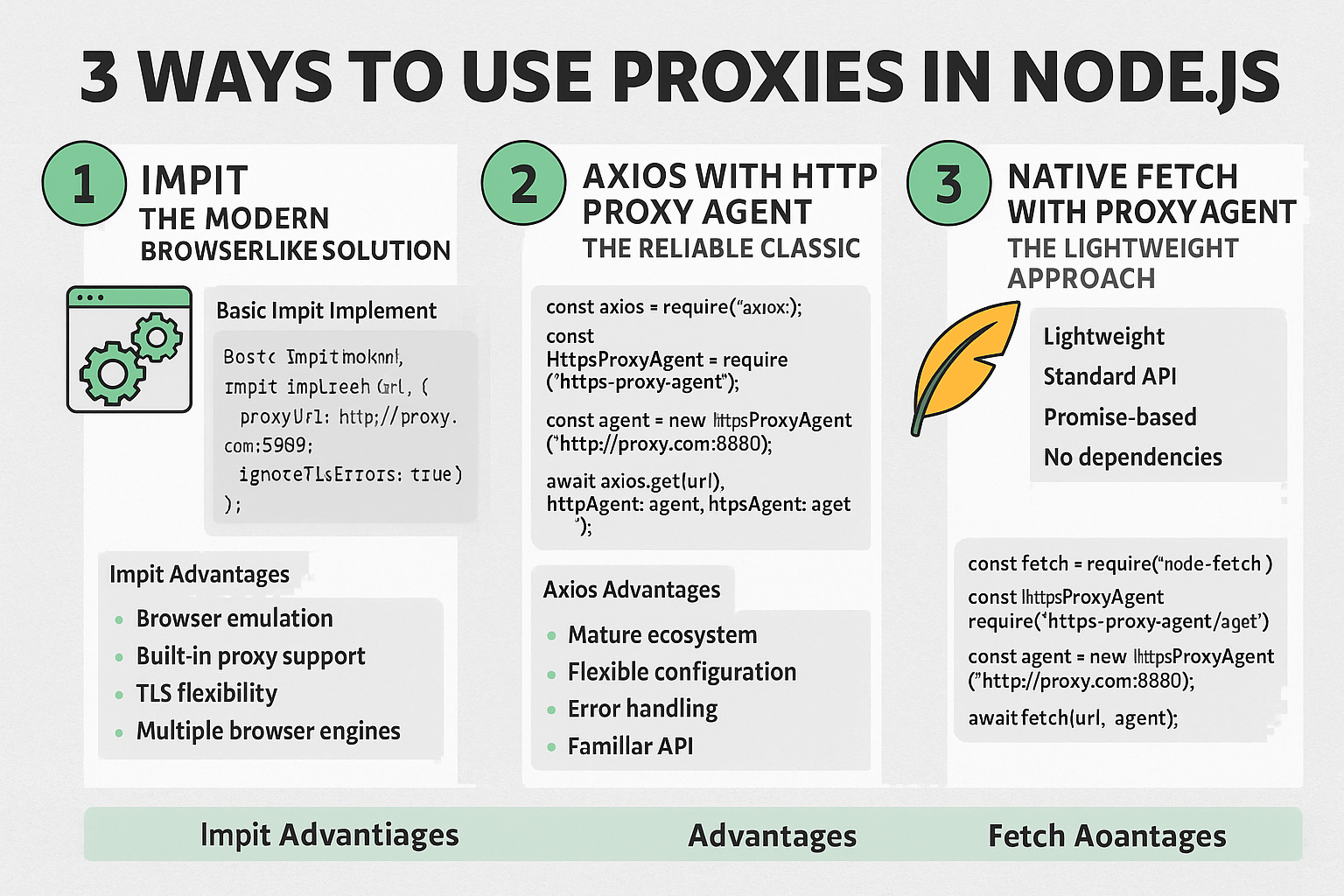
3 Ways to Use Proxies in Node.js: Impit, Axios, and Fetch
Learn three different methods for implementing proxy support in Node.js applications using Impit, Axios, and Fetch.
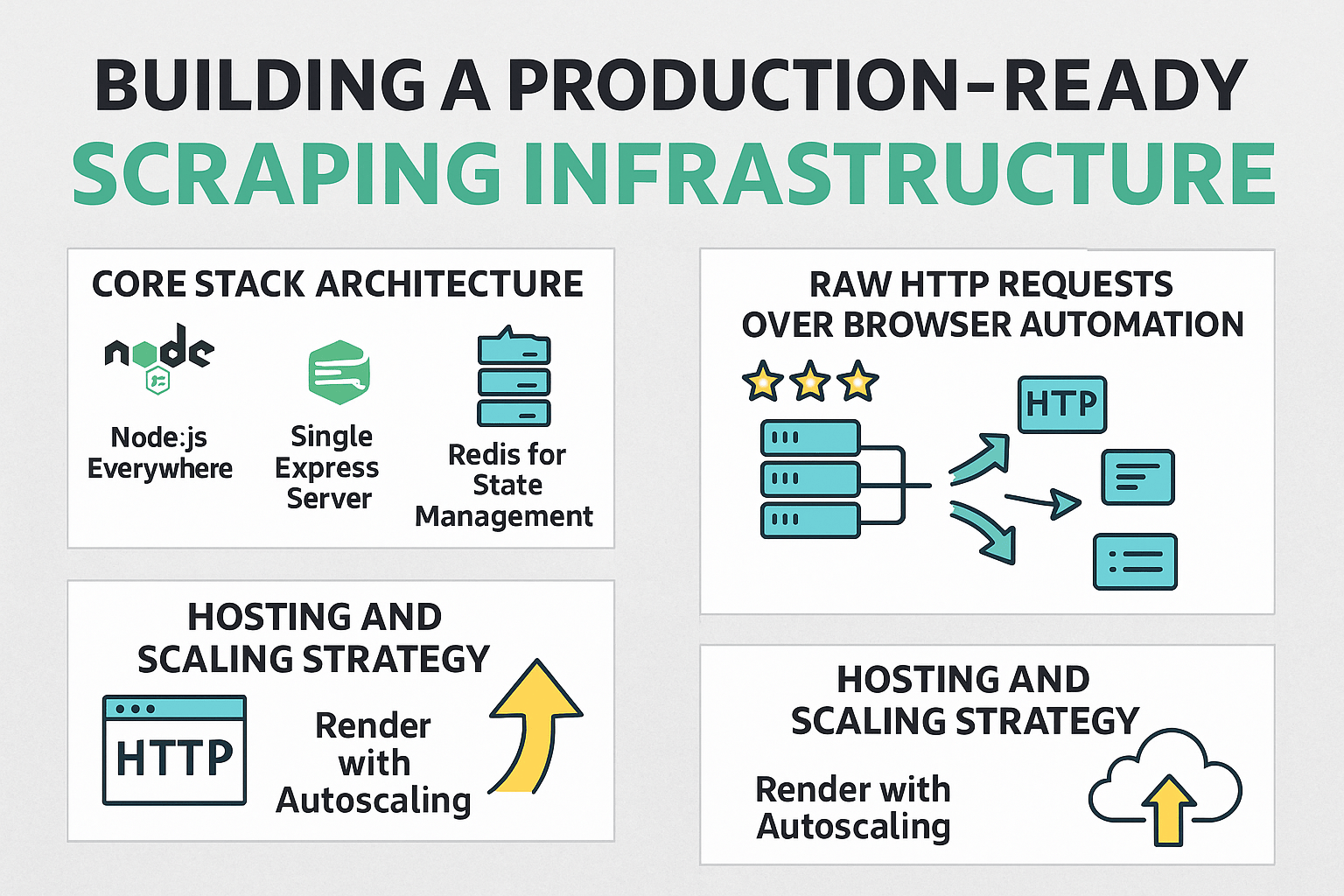
How to Build Production-Ready Scraping Infrastructure
This deep dive on Scrape Creators reveals the technical architecture powering a production scraping service thousands of requests daily.

The Ultimate Guide to Ad Library APIs: Facebook, Google, LinkedIn & Reddit
Discover how to access comprehensive advertising data from Facebook, Google, LinkedIn, and Reddit through their official ad libraries.

How to Scrape Instagram Data: The Complete Guide (2026)
This comprehensive guide covers profiles, posts, comments, and creative workarounds for Instagram's restrictions.

What Is Twitter's Pay-Per-Use API? Pricing, Risks, and Scraping Impact
Twitter is rolling out a pay-per-usage API model that could finally bridge the gap between their previous extremes of free-for-all and expensive access.

How to Find TikTok Creator Regions: The Hidden Method TikTok Doesn't Want You to Know
TikTok removed the region display from creator profiles, but the location data still exists hidden in video metadata. This simple scraping method uncovers it.
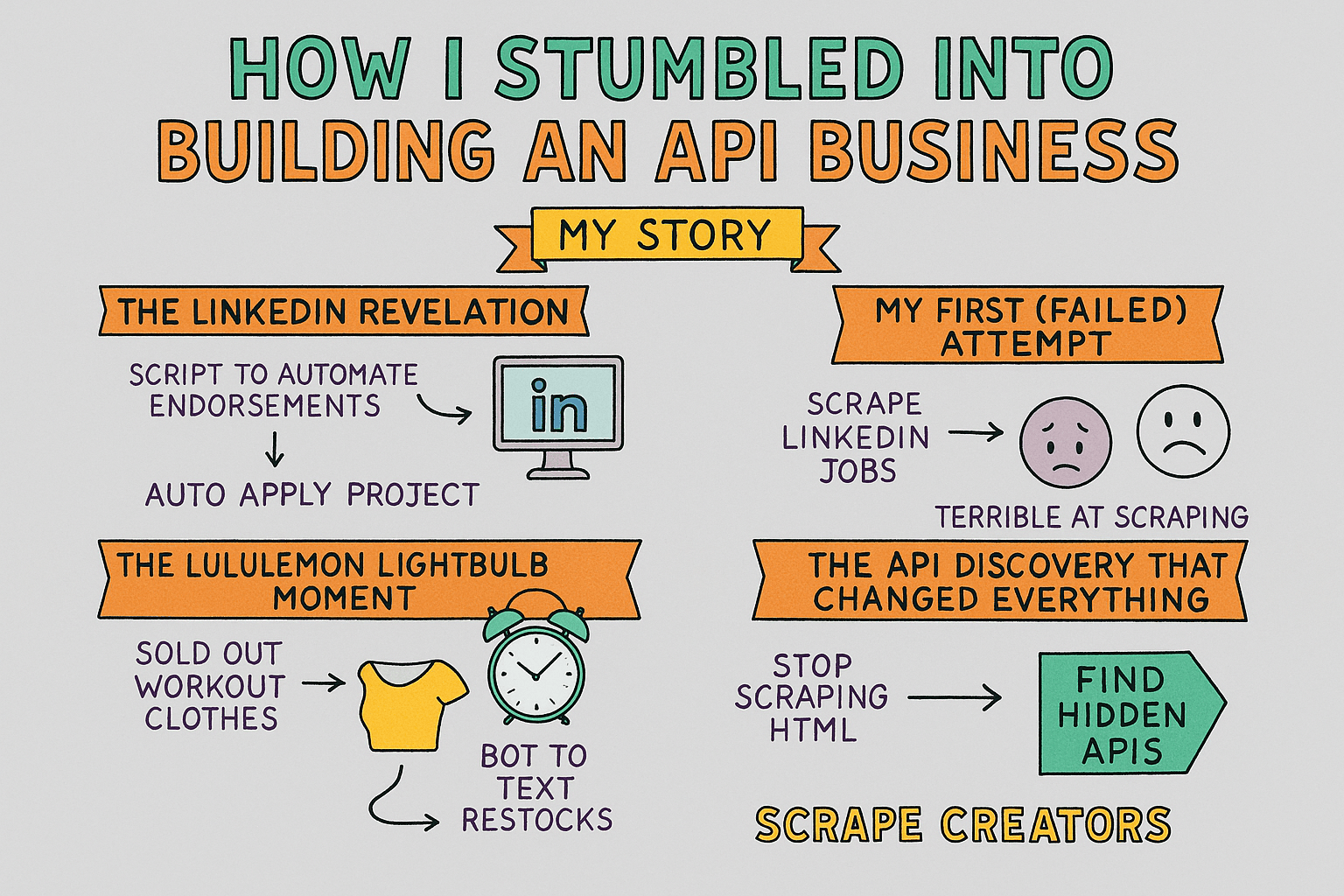
How I Built a Profitable Scraping API from a Lululemon Problem
The unexpected journey from coding bootcamp graduate to successful API entrepreneur and why the best business ideas come from solving real problems

How I Built a One-Person API Business That Extracts Structured Data from Every Social Platform
Learn how I built Scrape Creators as a solo developer, a profitable API business that provides instant access to structured data from social platforms.

What Are API Businesses? A Practical Guide for Solo Developers
API businesses are the lawn-mowing services of the internet. Simple, steady, and boring, but perfect for solo developers seeking freedom.
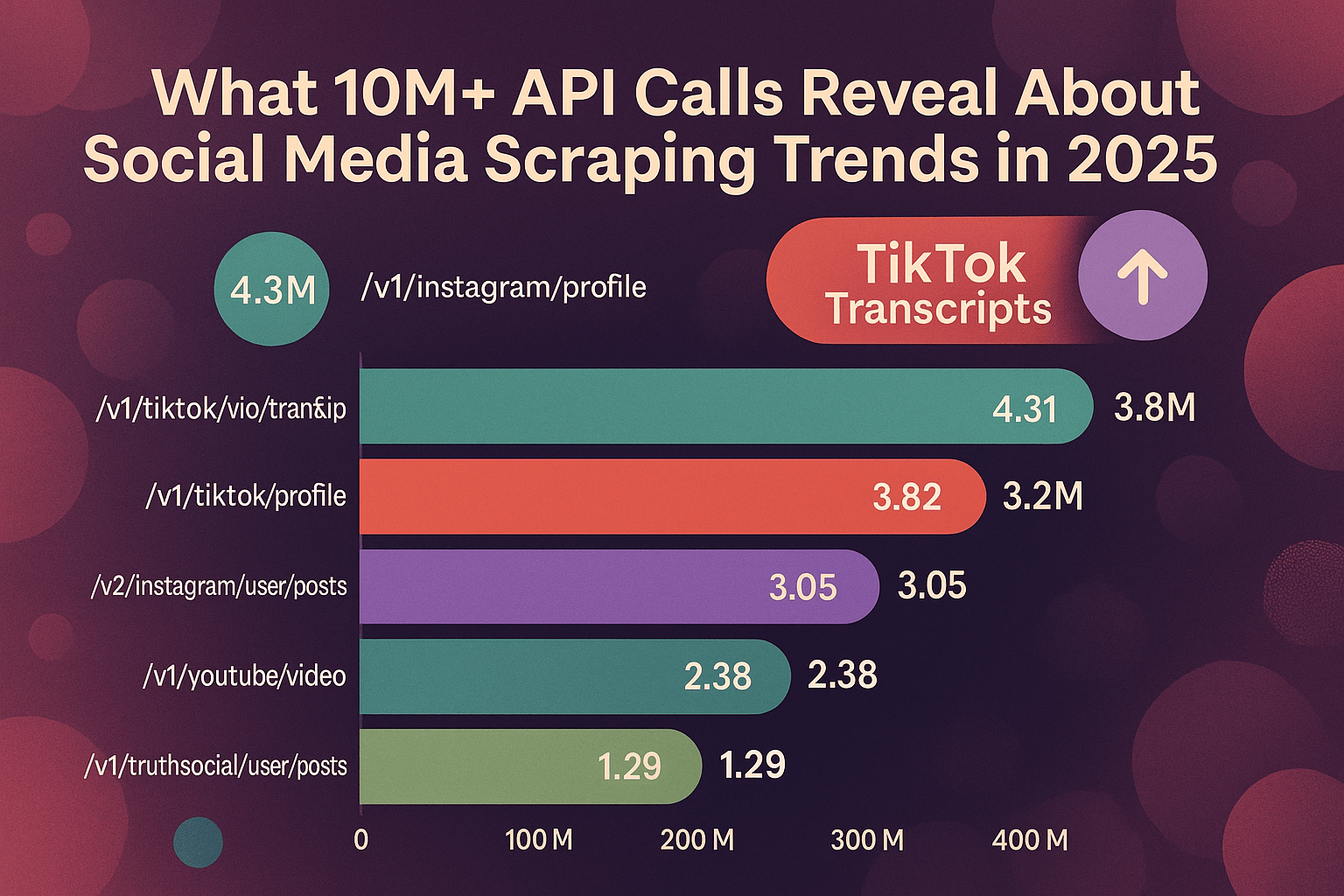
Social Media Scraping Trends: What 10M+ API Calls Reveal
Analysis of over 10 million Scrape Creators API calls reveals that Instagram profiles dominate scraping activity but TikTok transcripts are the surprising #2.

How to Use the Scrape Creators n8n Node Without HTTP Calls
The Scrape Creators Community Node is now available on n8n Cloud, eliminating the need for complex HTTP requests and API calls when scraping social media data.

What Happens When Social Media Companies Catch You Scraping? A Platform-by-Platform Guide
Here's what you can realistically expect from each major platform when they discover your scraping operations.

Is Web Scraping Legal? A Guide Based on Recent Court Rulings
Multiple federal court rulings against Meta and Twitter, have established that web scraping publicly accessible data is legal
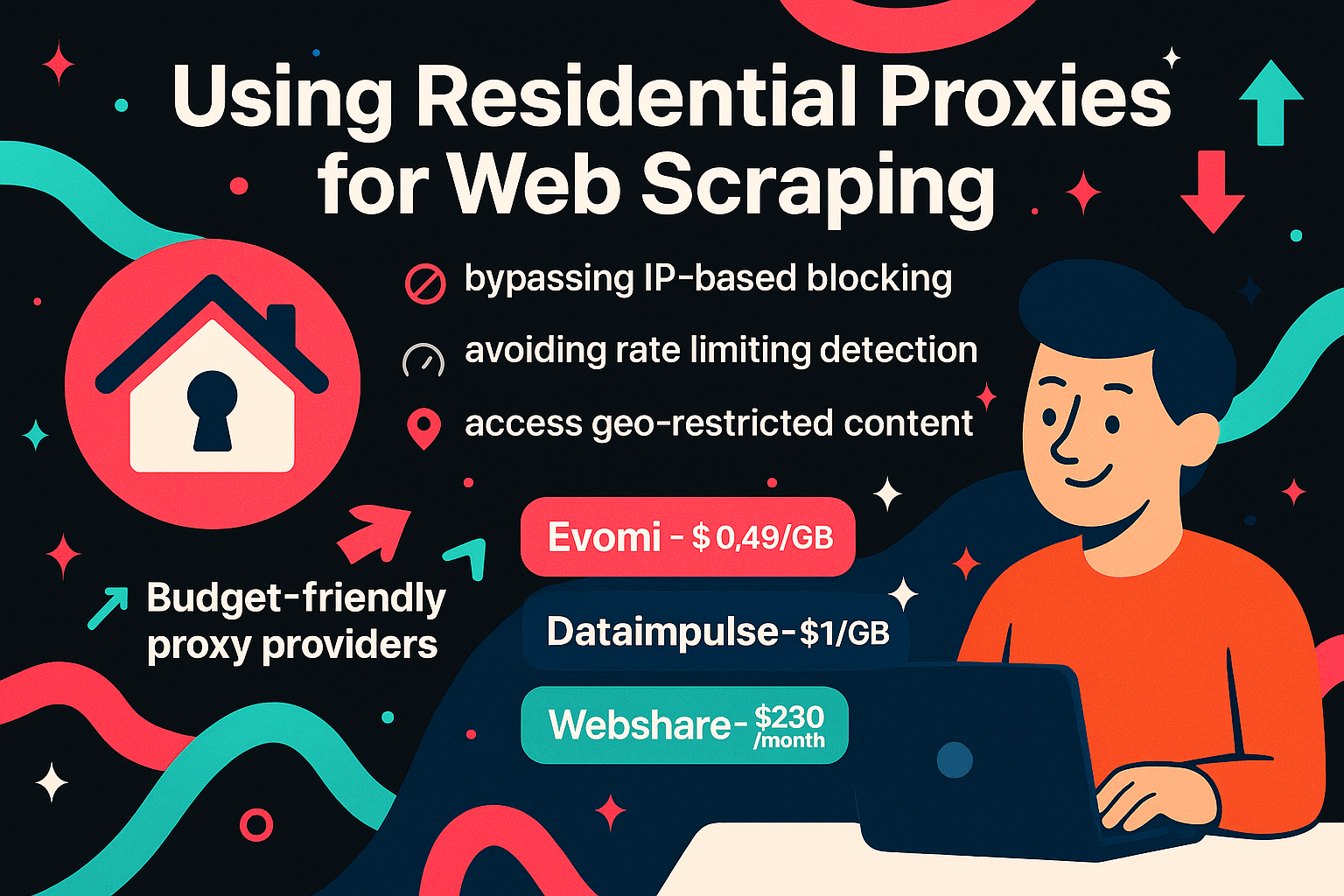
Best Cheap Residential Proxies for Web Scraping
Cheap and reliable residential proxy options for web scraping include Evomi at $0.49/GB, Dataimpulse at $1/GB, and Webshare for $230/month.

How to Solve TikTok Slider Captchas: A Developer's Guide
Learn how to programmatically solve TikTok's slider captchas using Puppeteer and SadCaptcha API when scraping TikTok Shop or other TikTok content.
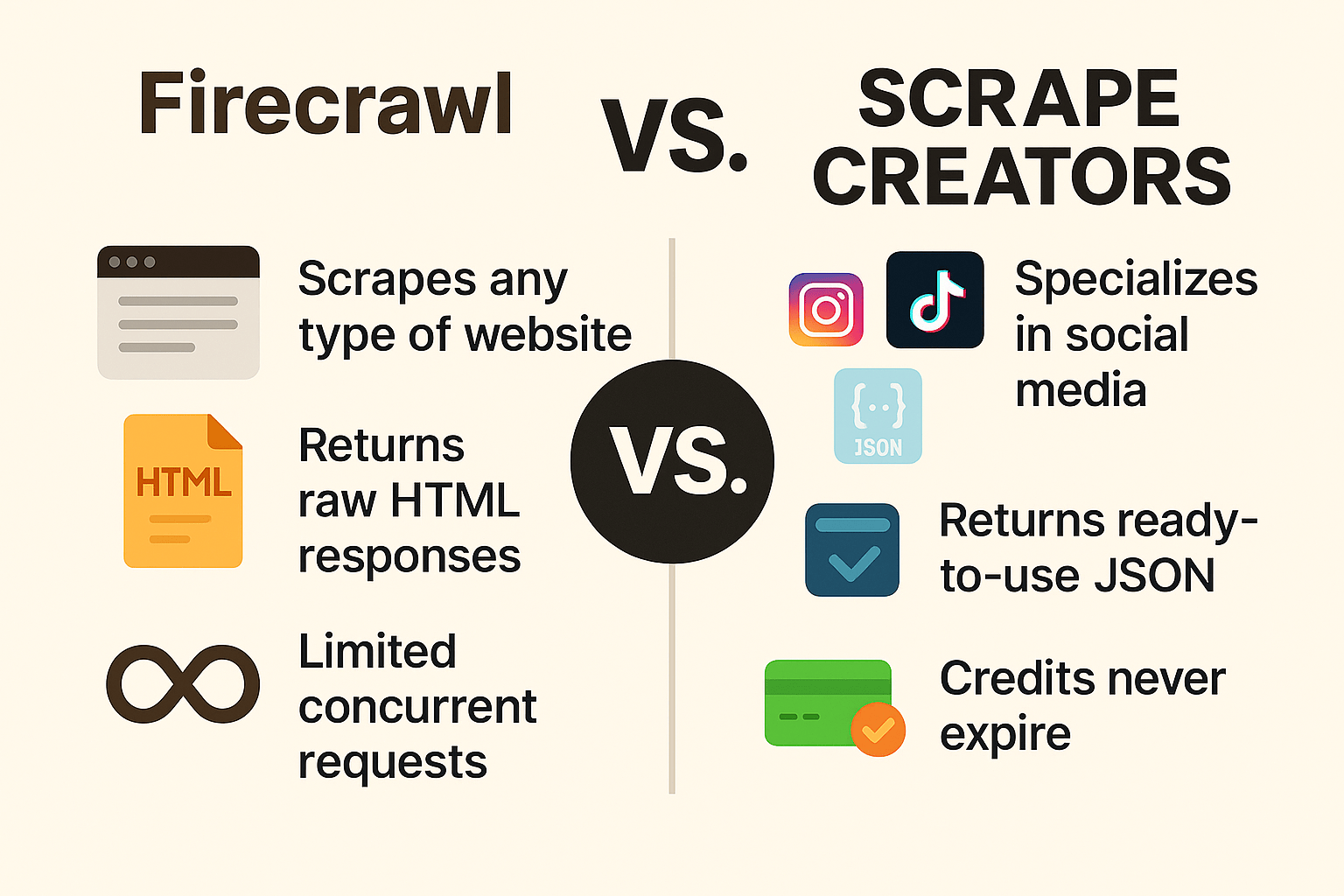
Firecrawl vs Scrape Creators: A Detailed Platform Comparison
Firecrawl handles any website with HTML responses, while Scrape Creators specializes in social media with ready-to-use JSON data.
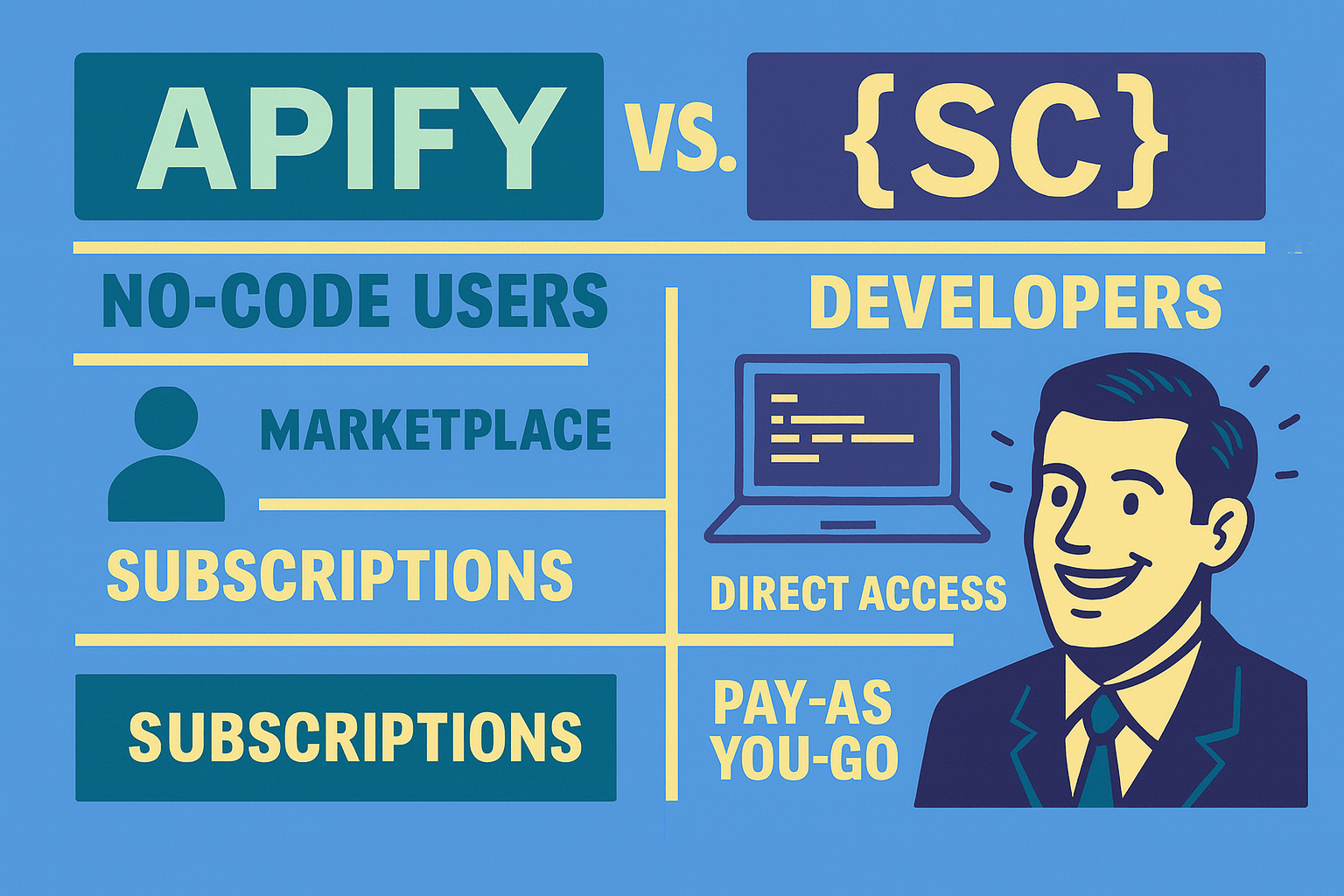
Apify vs Scrape Creators: Understanding the Key Differences
Apify focuses on no-code users with a marketplace model, while Scrape Creators prioritizes developers with direct creator access and simplified pricing.

Scrape Creators vs Scraping Bee: A Comprehensive Comparison
Scraping Bee handles any website but returns raw HTML, while Scrape Creators focuses exclusively on social media with ready-to-use JSON responses.

Social Media Scraping in 2026: Platform Rules, Risks, and Workarounds
Social media scraping enforcement varies wildly across platforms. Learn which platforms fight back and which don't care.

How to Access ESPN's Hidden API for Free Sports Data
Discover how to access ESPN’s hidden API and pull live sports data for free with simple GET requests.

Why You Shouldn't Use Puppeteer or Selenium for Web Scraping
Puppeteer and Selenium are slow, costly, and detectable. Learn why they’re a last resort for scraping and what to use instead.

The Legality of Scraping Twitter: A Developer's Guide
Scraping Twitter in 2025? Learn what’s legal, what’s not, and how developers can safely access Twitter data without risking lawsuits or bans.
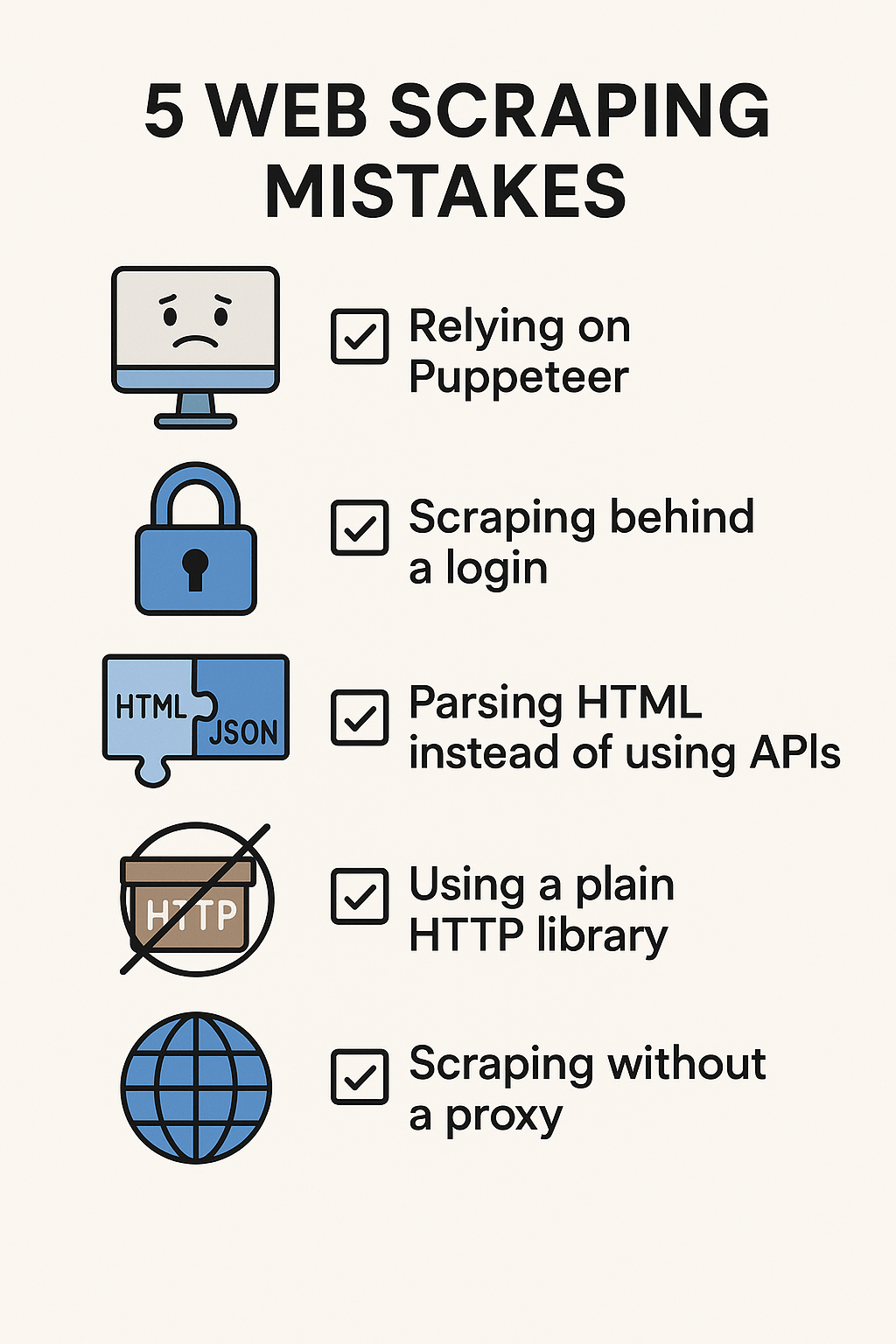
Web Scraping Best Practices: 5 Common Mistakes to Avoid
Learn the 5 most common web scraping mistakes (and how to avoid them). From Puppeteer pitfalls to proxy best practices, here’s how to scrape smarter.

How to Use TikTok Comments for Investment Research
Discover how one investor turned $20K into $80M by reading TikTok comments, and how you can automate the process with Scrape Creators API.
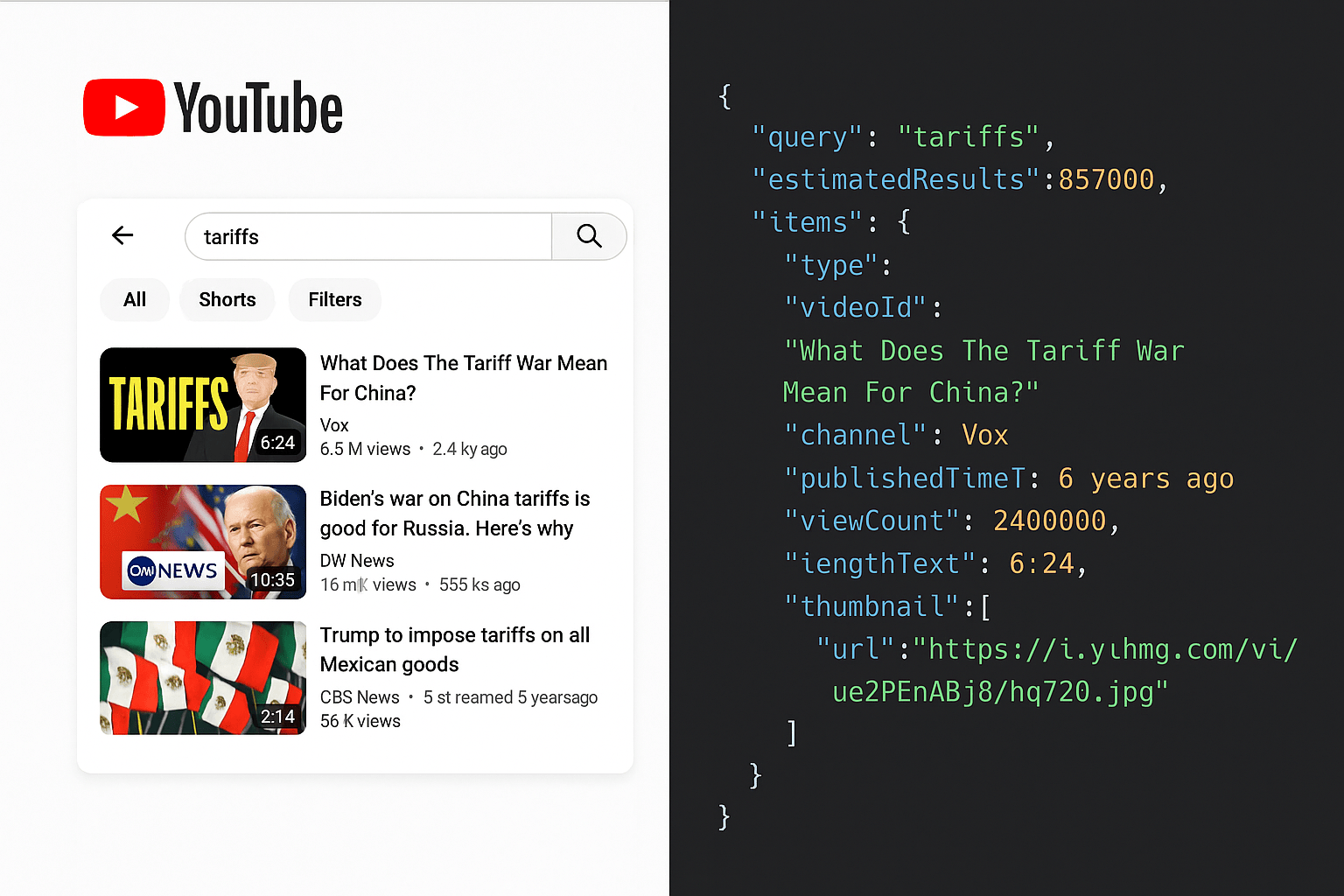
How to Scrape YouTube Videos, Shorts, Transcripts, and Comments
Scrape Creators Unofficial YouTube API lets you search videos & shorts, fetch channel details, get lightning fast transcripts, and extract comments. In real time
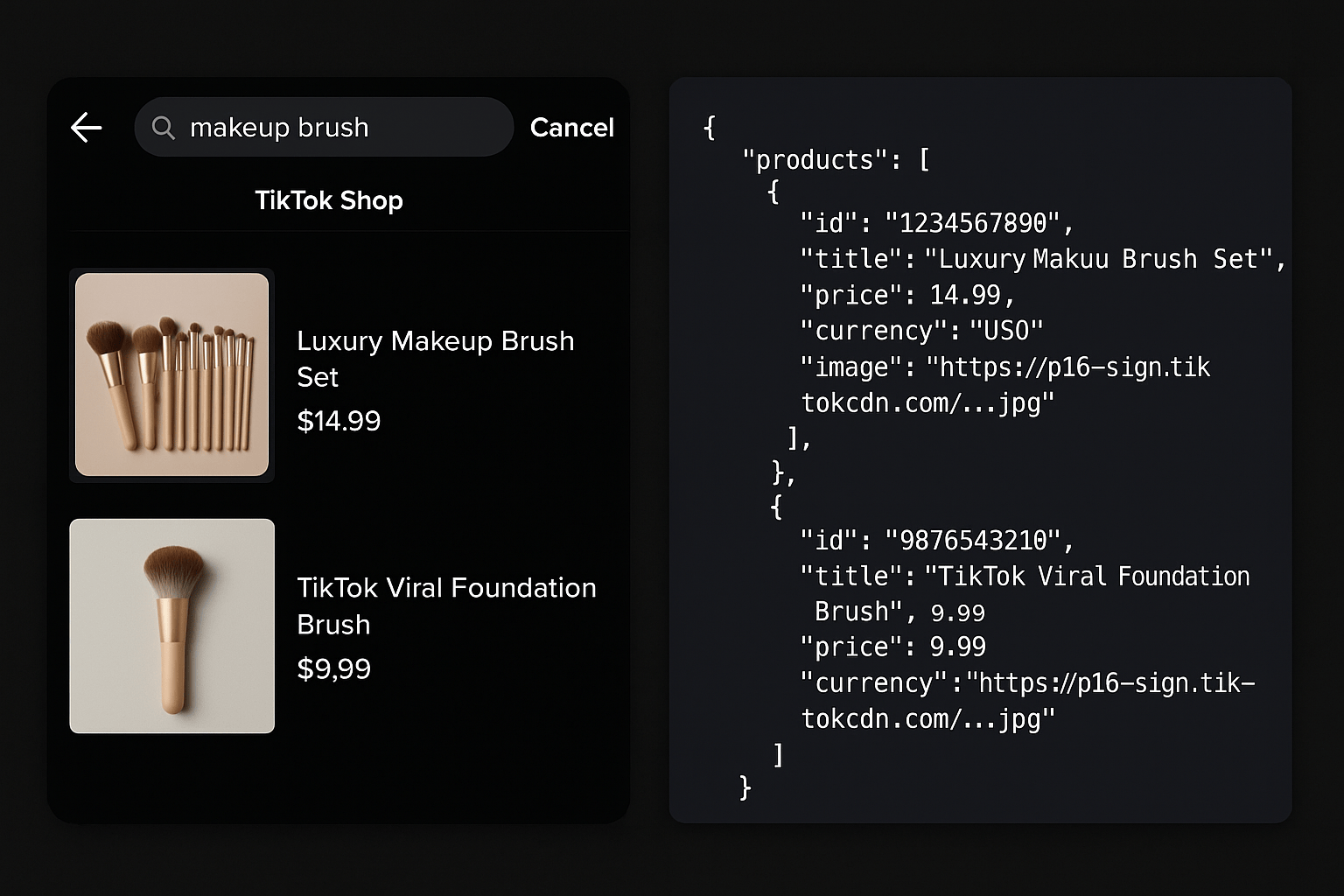
How to Search and Scrape TikTok Shop Products
Search TikTok Shop by keyword, list every product in a store, then hydrate details and promo videos. Covers search, shop catalog, product detail, and analytics workflows.
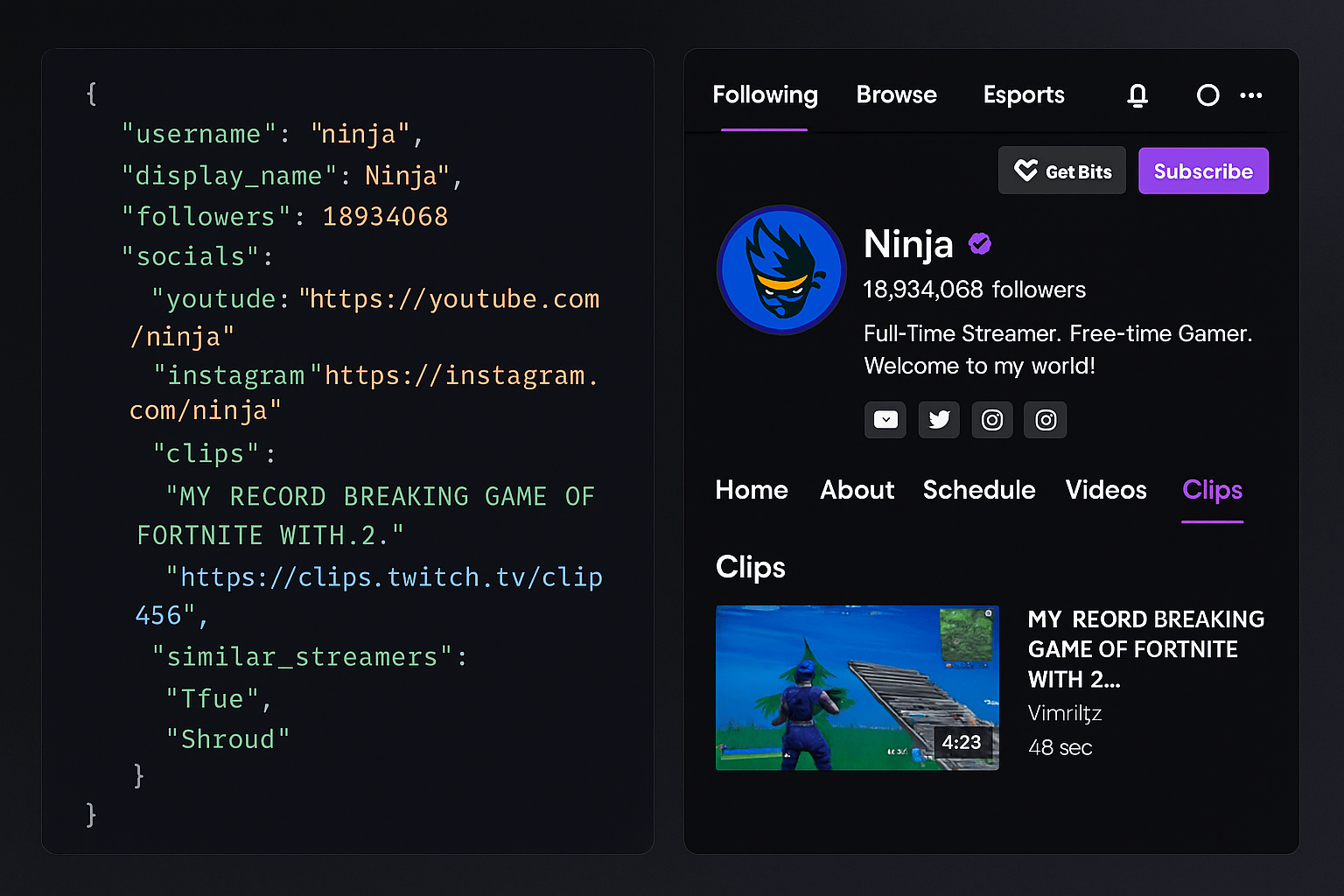
How to Scrape Twitch Creator Profiles with an Unofficial API
Scrape Twitch profiles with the Scrape Creators Unofficial Twitch Profile API. Get follower counts, social links, clips, and similar streamer data in seconds.

How to Scrape Threads Profiles, Posts, and Keywords
Scrape public Threads profiles, posts, and keywords instantly with the Scrape Creators Unofficial Threads API, no business account or app required.

How to Get Pinterest Data with an Unofficial Pinterest API
Scrape Pinterest pins, boards, and user pins instantly with JSON results, no business account needed. Get images, links, videos, recipes, and more fast.

Best Pay-As-You-Go Scraping APIs (No Monthly Commitment Required)
Tired of monthly scraping API subscriptions? Discover the only true pay-as-you-go web scraping APIs for social media and Google data, plus other popular options.

5 Best Proxy Providers for Web Scraping (Pricing and Performance)
Looking for the best proxy for scraping in 2025? Here's my honest review of 5 proxy providers I've actually used, what works, what sucks, and what's worth it.
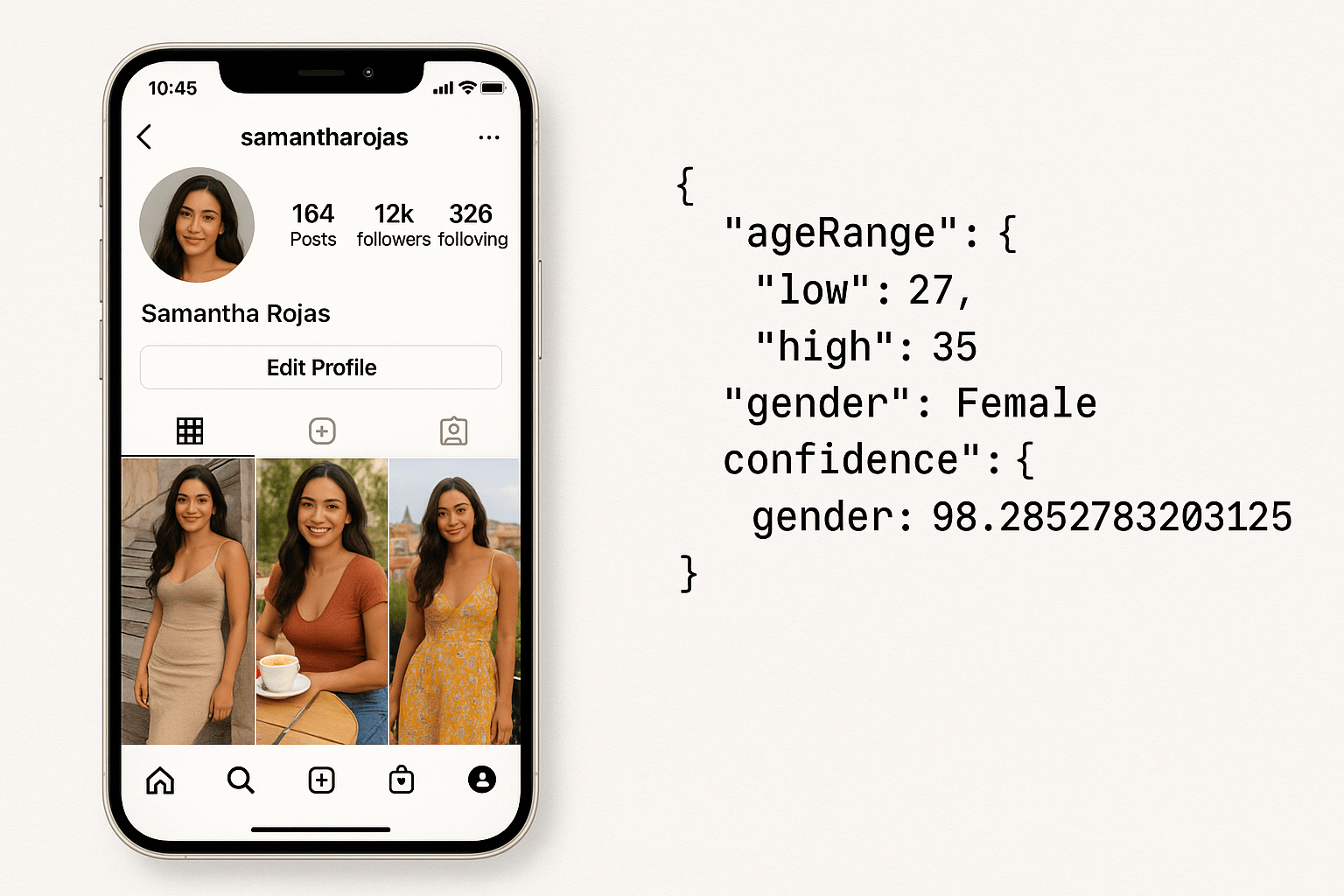
How to Get the Estimated Age & Gender of a Social Media Creator (Using Just Their Profile Pic)
Learn how to detect a creator’s age and gender using Amazon Rekognition or the Scrape Creators API. Perfect for influencer analysis or ad targeting.

How to See How Much a TikTok Shop is Making Daily (And Build Your Own FastMoss/Kalodata)
Learn how to estimate daily sales of any TikTok Shop product using Scrape Creators. Build your own FastMoss or Kalodata style tracker fast.
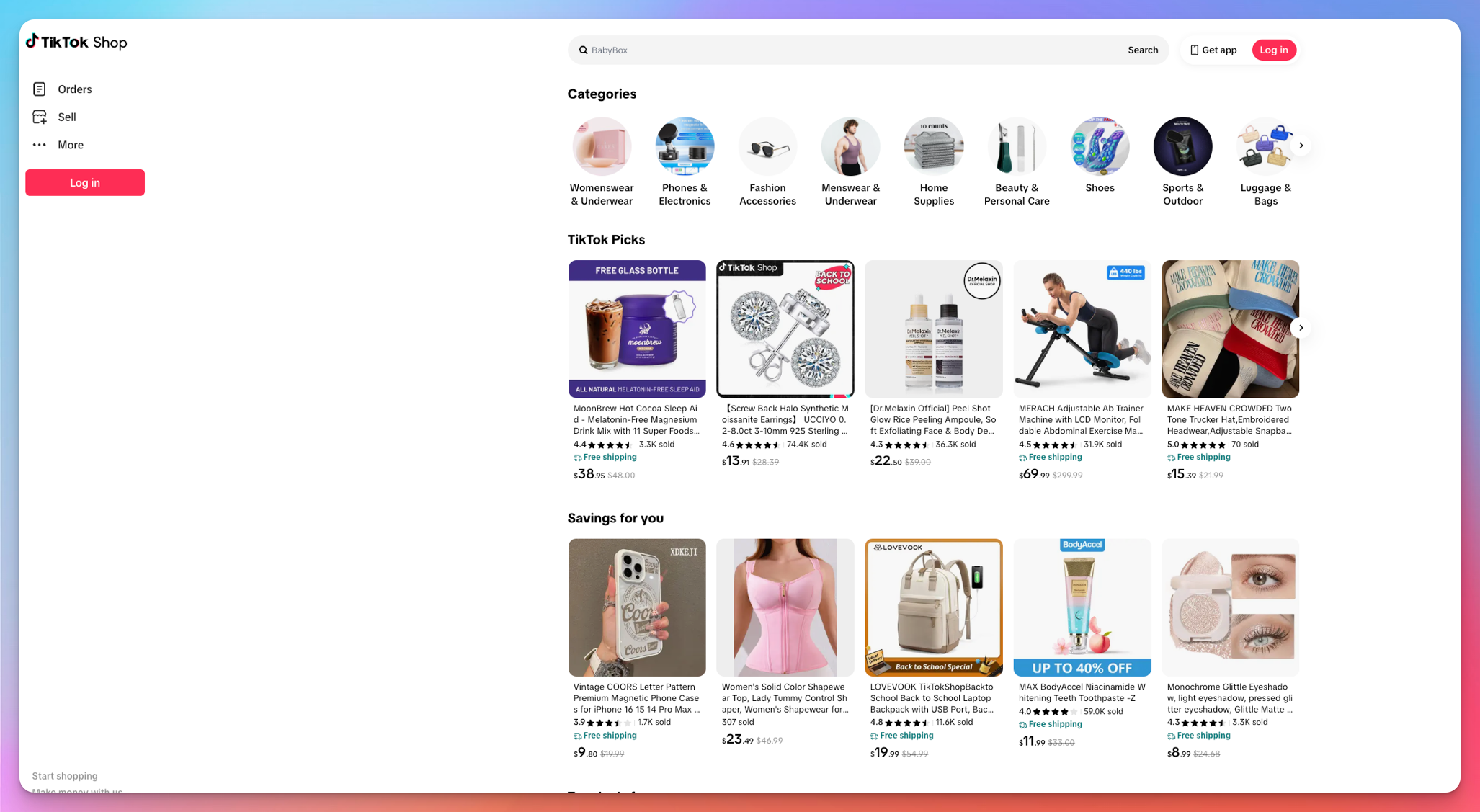
How to Access TikTok Shop on Desktop Without Logging In
TikTok Shop is now publicly available on desktop with no login required. Scrape product data, stock, affiliate videos, and more, easily and at scale.
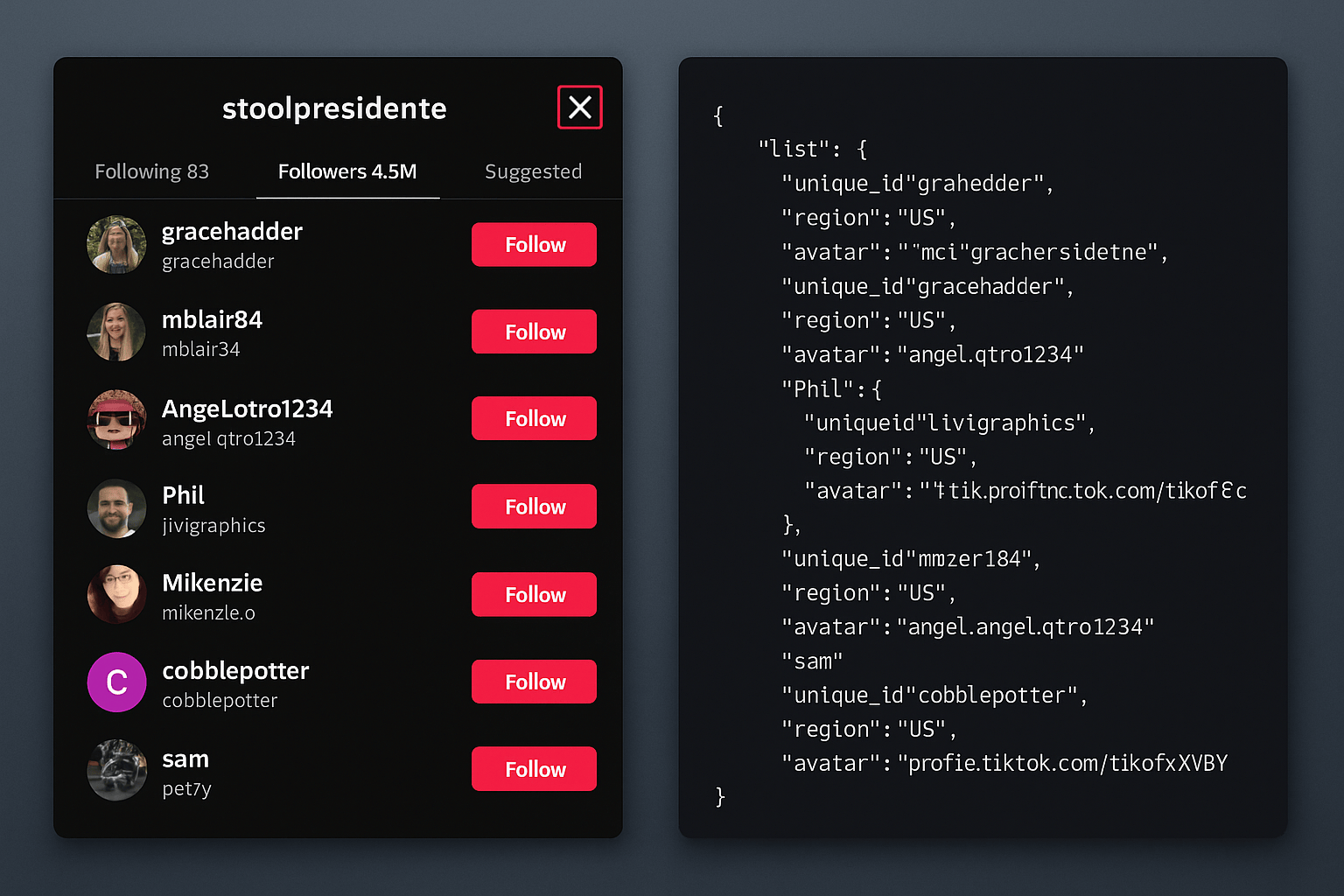
How to Get Someone’s TikTok Followers (and What You Can Do With Them)
Learn how to scrape someone’s TikTok followers with Scrape Creators. Get usernames, regions, avatars, then enrich the data to reveal demographics.
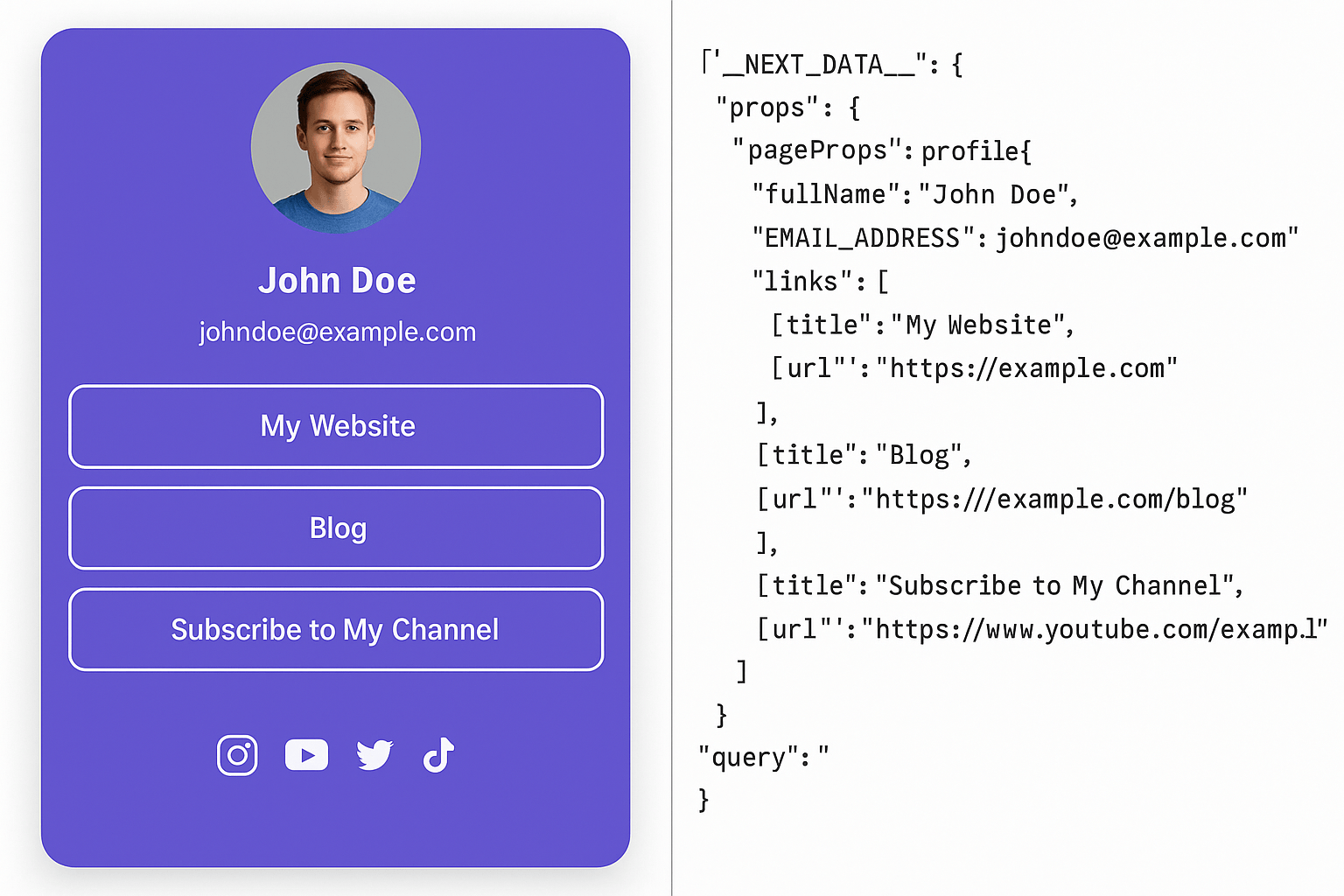
How to Scrape Linktree (and Find Emails or Social Links)
Learn how to scrape Linktree pages to find emails and social links using Node.js. A step-by-step guide with real-world examples and bonus tips.

How to Find Emails of YouTube Creators (Without Breaking the Rules)
Learn how to find YouTube influencer emails the right way. Explore software tools, APIs, and the best methods to get contact info from public profiles.
How to Find Emails and Followers of Public Instagram Accounts (3 Proven Methods)
Learn how to find emails and followers of public Instagram accounts using paid tools, scrapers, or behind the login APIs. Get results fast, even without coding.
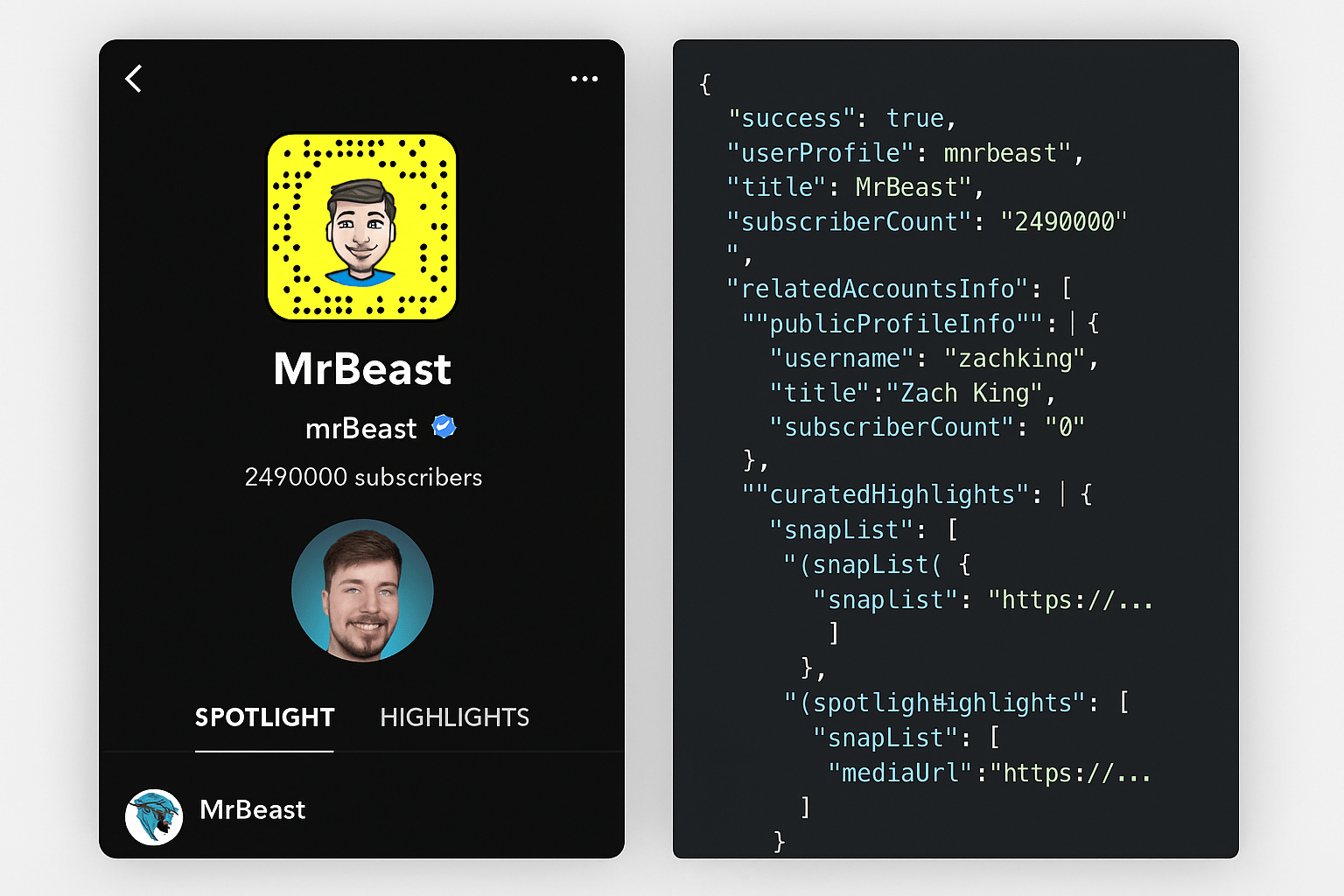
How to Get Snapchat Follower Counts, Stories, and Spotlights
Access public Snapchat follower counts, stories, and Spotlight data using Scrape Creators unofficial Snapchat API, no login required.
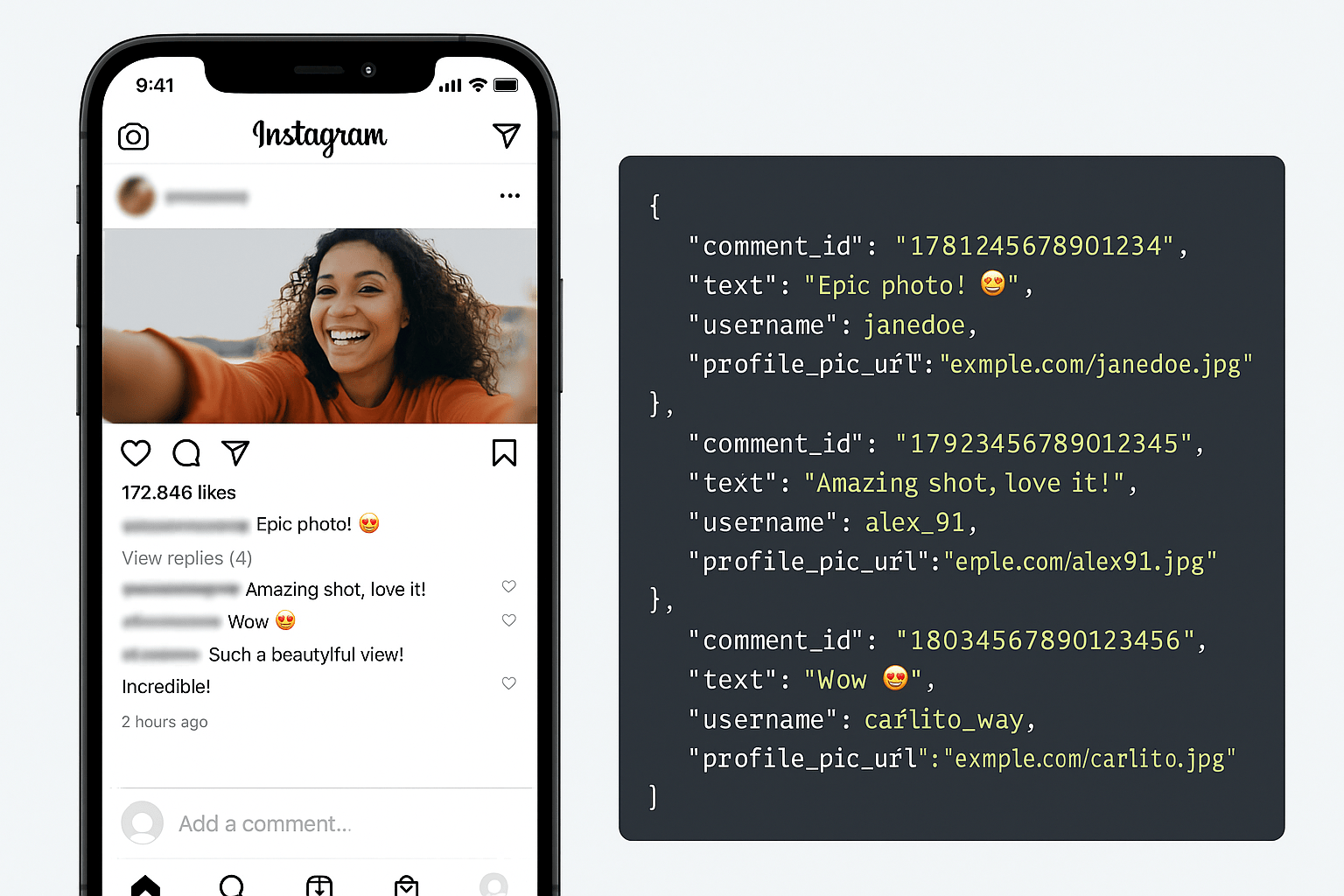
How to Scrape Instagram Comments from Any Public Post
Scrape Instagram comments from any public post using Scrape Creators. Perfect for UGC, sentiment analysis, lead gen, and more.

How to Scrape the X (Twitter) API: Developer Guide (2026)
Trying to scrape Twitter (X) data without spending thousands? In this 2026 guide, we break down safe, powerful, and affordable alternatives to the official X API

LinkedIn Scraping in 2026: Methods, Tools, and Legal Boundaries
Learn how to scrape LinkedIn profiles in 2026. Compare behind-the-login APIs with compliant public scrapers like Scrape Creators.

How to Scrape Facebook Group Posts and Comments
Scrape public Facebook group posts and comments easily with our new Facebook Groups API. Perfect for lead gen, research, and market analysis.

How to Get Reddit Posts, Comments, and Trends with an Unofficial API
Skip Reddit’s rate limits and complexity. This unofficial Reddit API gives you fast, reliable access to posts, comments, and search, with pay-as-you-go pricing.

How to Track Influencers and Analyze Instagram Bios at Scale
Get real-time access to Instagram bios, follower counts, recent posts, and related creators, with no login, no rate limits, and no app approval. Ideal for influencer tracking and marketing tools.
How to Spy on Your Competitors’ Facebook Ads with One API Call
Stop scrolling and start scraping. Learn how to spy on your competitors’ Facebook ads with just one API call using Scrape Creators, no login or rate limits required.
How to Find Out If a TikTok User Has a TikTok Shop
Learn how to programmatically detect if a TikTok user has a TikTok Shop using Scrape Creators. Great for marketers, UGC creators, SaaS tools, and agencies looking to sell services or analyze shop data at scale.
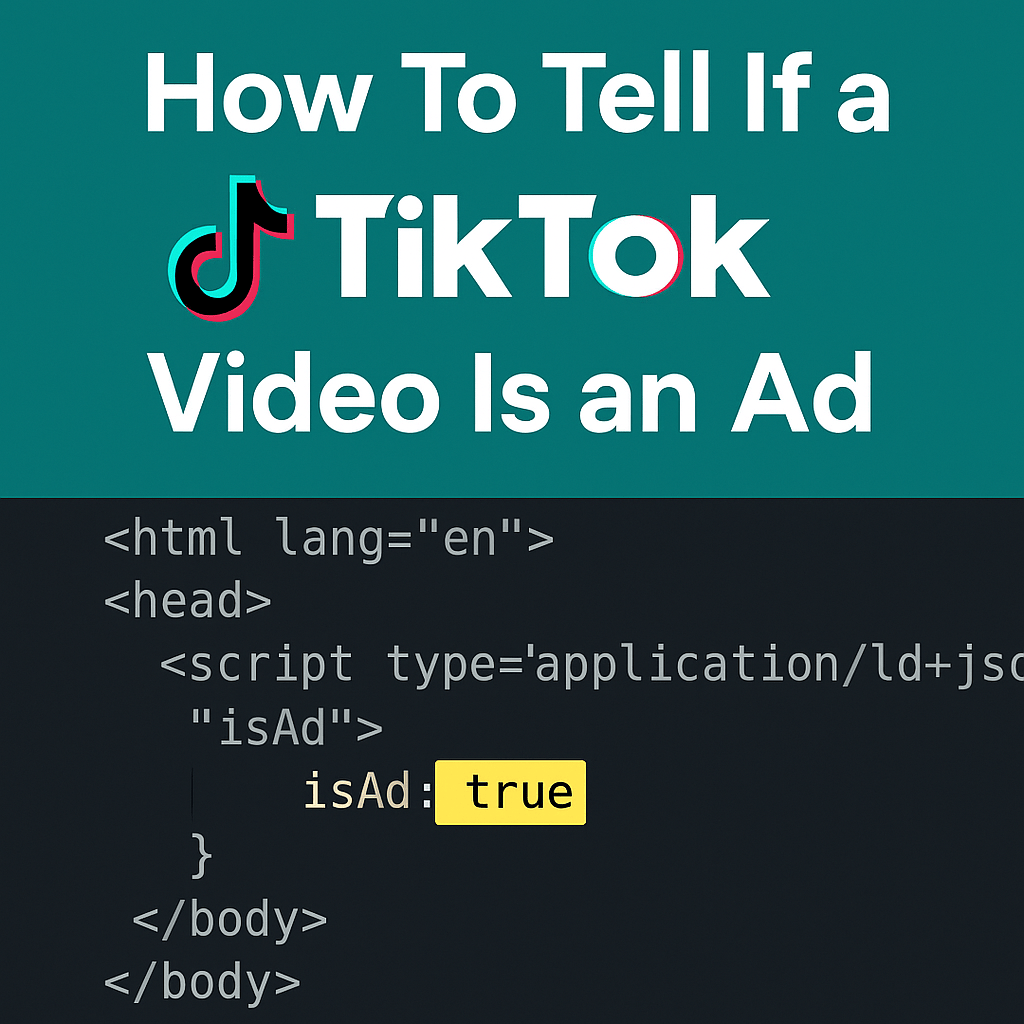
How to Tell If a TikTok Video Is an Ad
Want to know if a TikTok video was turned into an ad? Learn how to check the isAd flag in the HTML and why it matters for influencer and ad strategy.
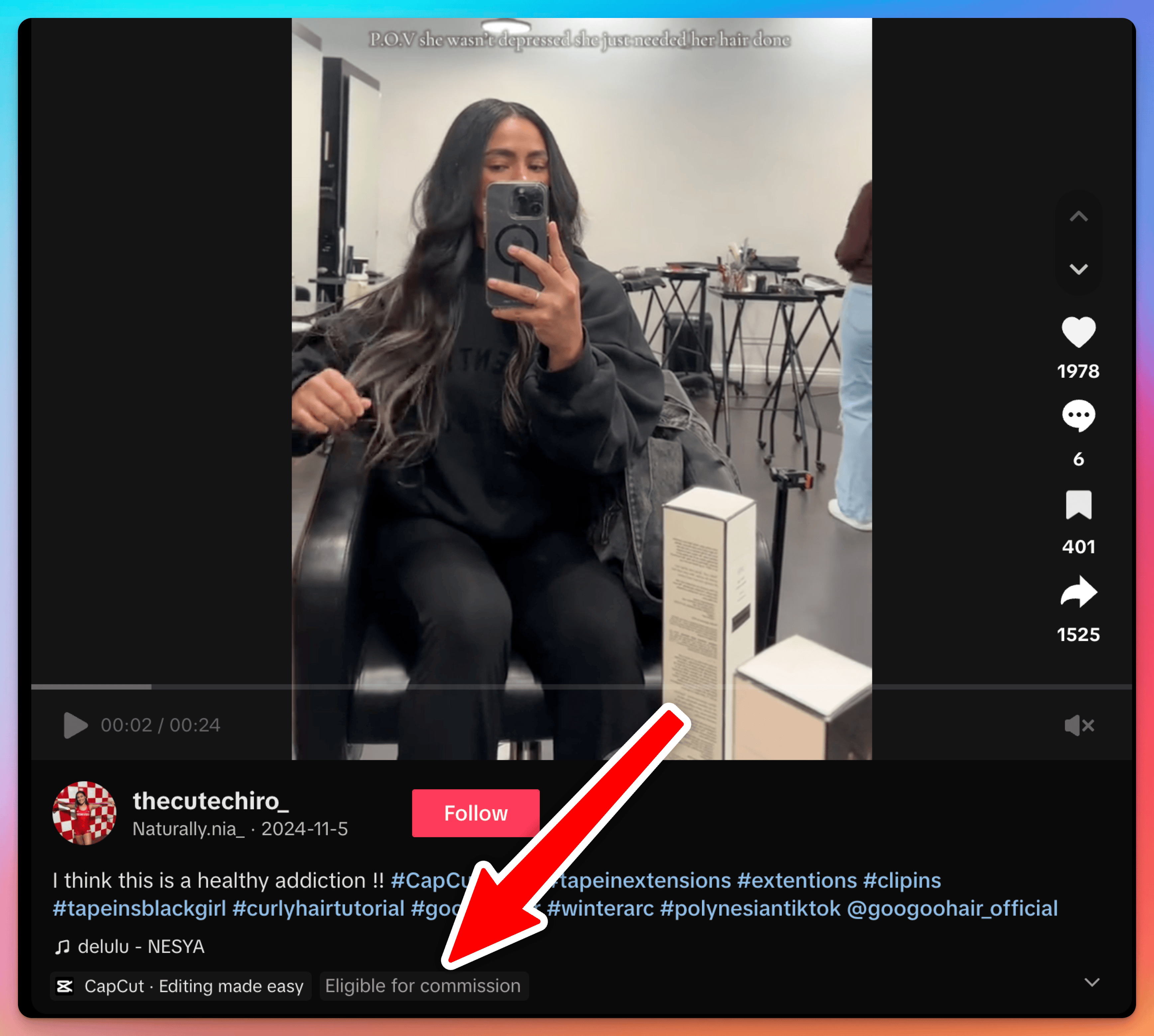
How to Tell If a TikTok Video Is Promoting a TikTok Shop Product
Learn how to spot the “Eligible for commission” label, identify affiliate content, and get this data via API.

Best Truth Social API for Tracking Trump's Posts
Want to get Trumps but not sure how? Automatically get them with our unofficial Truth Social API

How to Scrape Images from TikTok Slideshows
Ever wondered how to extract TikTok images from a TikTok photo carousel? This article explains exactly how to do it

How to Scrape YouTube Transcripts with Node.js
Scrape YouTube Transcripts fast with this method

How to Access Instagram Public Data Without Rate Limits
An Instagram public data API serves profiles and posts as JSON—without the Graph API's approval maze for read-only public fields. Official limits and app review slow down prototypes. Unofficial public endpoints help when you only need what's visible without lo…
How to Scrape the Meta Ad Library
Meta Ad Library scraping turns Facebook and Instagram ad transparency data into JSON—keyword search, page lookups, and creative detail. Paid social researchers need repeatable pulls, not one-off CSV exports from Meta's UI. In this guide, you'll learn: What you…