
Linktree pages pack creator contact data into one URL—emails, Instagram, YouTube, TikTok, and outbound links creators choose to publish.
Scraping Linktree means reading the __NEXT_DATA__ JSON blob Next.js embeds in each profile HTML. No login wall. No browser farm—just HTTP, Cheerio, and the right parse step.
That matters when you are building outreach lists, enriching CRM records, or mapping a creator’s full social footprint:
- Extract emails and social handles from public profiles
- Scale with proxies when you hit rate limits
- Discover profiles in bulk via Linktree’s public directory API
In this guide, you’ll learn:
- Why Linktree is a goldmine for creator contact data
- How Linktree stores profile data under the hood
- A Node.js scrape using got-scraping and Cheerio
- Proxy options, the discover API, and a prebuilt Linktree endpoint
Here’s the Node.js scrape step by step.
Why Scrape Linktree?
Linktree is a popular tool used by creators to display all their important links, emails, social media accounts, websites, and more. That makes it a goldmine for anyone looking to extract useful contact info like:
- Emails
- Social media links (Instagram, YouTube, TikTok, etc.)
- Websites or personal blogs
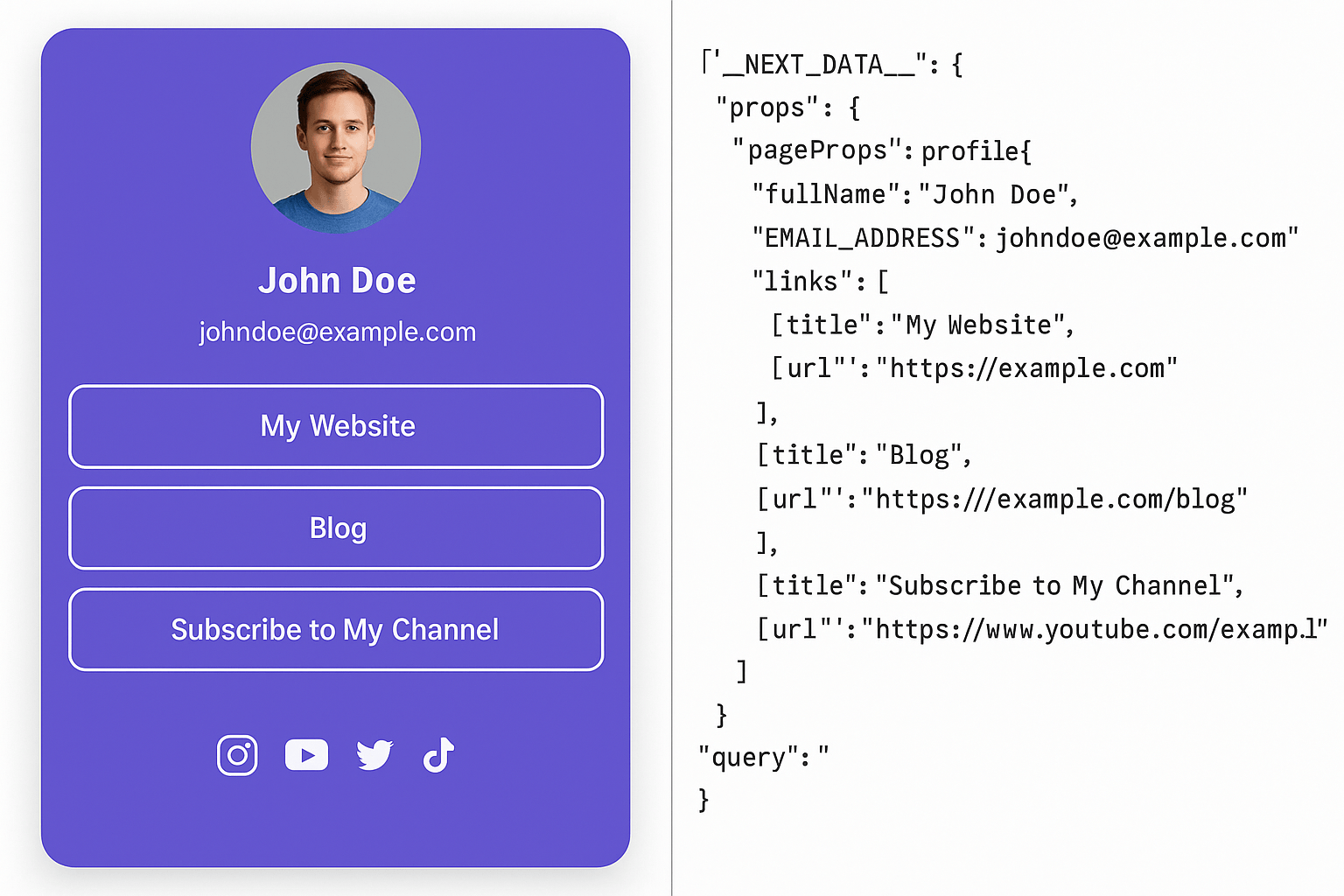
Step-by-Step: How Linktree Works Under the Hood
Let’s walk through scraping a Linktree page using this example: https://linktr.ee/miguelangeles
- Open Dev Tools Right-click → Inspect → Go to the Network tab.
- Refresh the Page The very first request is for the HTML document.
- **Click on the first request
**It should be
miguelangeles - Go to the response tab
- **Search for **
__NEXT_DATA__In the HTML response, search for__NEXT_DATA__. This is where Linktree stores a full JSON blob of the page’s data (thanks Next.js for making this super easy to scrape). This includes things like:
EMAIL_ADDRESS- Social links
- URLs
- Profile Data
Scrape Linktree with Node.js
Here’s how to do it in code using got-scraping and cheerio:
import { gotScraping } from 'got-scraping'
import * as cheerio from 'cheerio'
async function scrapeLinktree(username) {
const url = `https://linktr.ee/${username}`
const response = await gotScraping({
url,
proxyUrl: "PROXY_URL_HERE"
})
const $ = cheerio.load(body)
const nextScript = $('#__NEXT_DATA__').html()
const data = JSON.parse(nextScript)
return data;
}
scrapeLinktree('miguelangeles').then(console.log)
Use a Proxy for Scale
If you’re scraping lots of Linktree pages, use a proxy to avoid rate limits or bans. Good options include:
Bonus: Scrape Linktree’s Public Directory
You can discover thousands of profiles using their discover API:
https://linktr.ee/discover/_next/data/zd5lRJ4hQhc2caWwdfD1Z/profile-directory/c/all/page-1.json?category=all&page=page-1
Just change the page number to increment.
⚠️ If Linktree updates their site, that zd5lRJ4hQhc2caWwdfD1Z hash will change. To get the latest:
- Visit https://linktr.ee/discover/profile-directory/c/all/page-1/
- Open Dev Tools → Network → Watch for requests when you paginate
Or Use our Prebuilt Linktree Scraper!
Don’t want to code this yourself?
Use my Linktree Scraper, quick, easy, and real-time.
Need more? Scrape Creators also supports:
- TikTok
- YouTube
- Truth Social
- Ad libraries for Meta, LinkedIn, Google, and Reddit
Sign up for 100 free requests, no credit card required!

