

Instagram remains one of the most valuable sources of social media data, but scraping it requires careful navigation of both technical challenges and legal considerations.
The platform offers two distinct data territories: public information accessible without login, and private data that requires authentication.
The Two Worlds of Instagram Scraping
Instagram data exists in two distinct realms, and understanding the difference is crucial for anyone considering data extraction from the platform.
- Public Data (Safe Zone): Information visible without logging in
- Private Data (Risk Zone): Content requiring authentication to access
The fundamental rule is simple: if you can see it in an incognito browser without logging in, it’s generally safe to scrape. If you need to be logged in to view it, you’re entering risky territory where Meta’s enforcement becomes aggressive.
What You Can Safely Scrape (Public Data)
Opening Instagram in an incognito browser reveals exactly what’s available for public scraping. While Instagram has become increasingly restrictive about public data access, several valuable data points remain accessible:
Profile Information
Public profiles offer a wealth of basic information including bio content, post counts, follower numbers (though not the actual follower lists), website links, and profile images. Notably, email addresses aren’t directly exposed unless creators include them in their bio text.
Post Data
Individual posts provide comprehensive metrics including like counts, comment counts, view numbers for videos, full captions, and access to the actual media files (images and videos). This represents some of the most valuable public data available.
Comment Analysis
While viral posts may not expose every single comment due to Instagram’s loading limitations, a substantial portion of comments remain accessible through public scraping. This provides valuable sentiment analysis and engagement data.
Reel Transcripts
Instagram automatically generates transcripts for many Reels, and these transcripts are often accessible through public endpoints, providing valuable content analysis opportunities.
Story Highlights
Unlike current stories (which require login access), story highlights remain publicly accessible and can provide insights into a creator’s key content themes and messaging.
Creative Workarounds for Limitations
Instagram’s restrictions on public search functionality have forced creative solutions. Since Instagram no longer exposes search results publicly, clever scrapers have developed workarounds:
Google Site Search Method: Using Google’s site search with the query site:instagram.com/p/ [keyword] can reveal relevant posts. Once you have post URLs from Google results, you can then scrape detailed statistics using standard post endpoints.
This method effectively bypasses Instagram’s search restrictions by leveraging Google’s indexing of Instagram content.
The Forbidden Zone: Private Data
Behind Instagram’s login wall lies significantly more valuable information, but accessing it comes with substantial risks:
- Contact Information: Email addresses and phone numbers from profile contact buttons
- Social Networks: Complete followers and following lists
- Native Search: Direct hashtag and keyword search within Instagram
- Engagement Metrics: Share counts and other private metrics
- Current Stories: Active story content (as opposed to archived highlights)
While this data is undeniably valuable for marketing, research, and competitive analysis, Meta’s enforcement against behind-the-login scraping is notoriously aggressive.
The Risk-Reward Calculation
Meta has made it clear that unauthorized access to private Instagram data violates their terms of service, and they actively pursue enforcement action. This includes:
- Account suspensions and bans
- IP address blocking
- Legal action against large-scale operations
- Technical countermeasures that make scraping increasingly difficult
However, the data behind the login wall often represents the most valuable information for business intelligence, marketing research, and competitive analysis.
Technical Implementation Approaches
For those choosing the safer public scraping route, several technical approaches exist:
- Direct API Calls: Making HTTP requests to Instagram’s public endpoints that power their web interface
- Browser Automation: Using tools like Selenium or Puppeteer to programmatically browse public pages
- Specialized Services: Third-party APIs designed specifically for Instagram data extraction
The choice depends on scale requirements, technical expertise, and risk tolerance.
Reverse Engineering Public Instagram Endpoints
First, we only discuss public data here. If you try to scrape through a full browser, tools like Puppeteer or Selenium are often easy to detect before you ever reach useful JSON.
To find the HTTP calls behind a public profile (follower counts, bio, links, and similar fields), open a profile in your browser, use DevTools Network filtered to Fetch/XHR, and watch requests while you interact with the page (for example, open Related accounts). Look for requests such as `web_profile_info` that return structured profile data you can replay with a capable HTTP client.
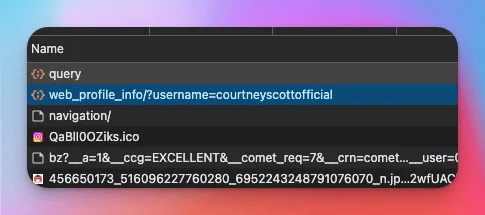
Use a resilient HTTP stack (for example got-scraping from Apify) and residential proxies for anything beyond trivial volume. Reuse browser-like headers when the endpoint expects them, and watch for cursor-based pagination in payloads when you page through lists.
If you want this already packaged, the Scrape Creators Instagram profile endpoint returns public profile data without maintaining your own scraper.
Legal and Ethical Considerations
Public data scraping generally falls under fair use provisions, especially when:
- Only publicly available information is accessed
- Data is used for research, journalism, or legitimate business purposes
- Scraping doesn’t overload Instagram’s servers
- The scraped data isn’t redistributed commercially without permission
However, behind-the-login scraping enters murkier legal territory and may violate both terms of service and potentially computer fraud laws, depending on jurisdiction and implementation.
Scaling Considerations
Public Instagram scraping can be scaled effectively with proper infrastructure:
- Rate Limiting: Respecting Instagram’s server capacity to avoid detection
- Proxy Rotation: Distributing requests across multiple IP addresses
- Data Storage: Efficiently storing and organizing extracted information
- Error Handling: Managing Instagram’s anti-scraping measures gracefully
The Evolution of Instagram’s Defenses
Instagram continuously evolves its anti-scraping measures, including:
- Implementing more sophisticated bot detection
- Reducing publicly available data
- Adding CAPTCHA challenges
- Implementing rate limiting and IP blocking
Successful long-term scraping operations must adapt to these changing conditions.
Alternative Approaches
For businesses requiring Instagram data, several alternatives to direct scraping exist:
- Official Instagram API: Limited but legitimate access to certain data types
- Third-Party Services: Specialized companies offering Instagram data through legitimate partnerships
- Manual Collection: For smaller-scale needs, manual data collection remains viable
Future Outlook
The Instagram scraping landscape continues to evolve, with the platform generally becoming more restrictive over time. The trend suggests:
- Decreasing public data availability
- Increased enforcement against unauthorized access
- Growing demand for legitimate data access solutions
- Rising costs for Instagram marketing intelligence

