
Building tools to extract and analyze Twitter threads has become increasingly valuable for researchers, content creators, and marketers.
With Twitter’s official API becoming more restrictive and expensive, alternative approaches have emerged.
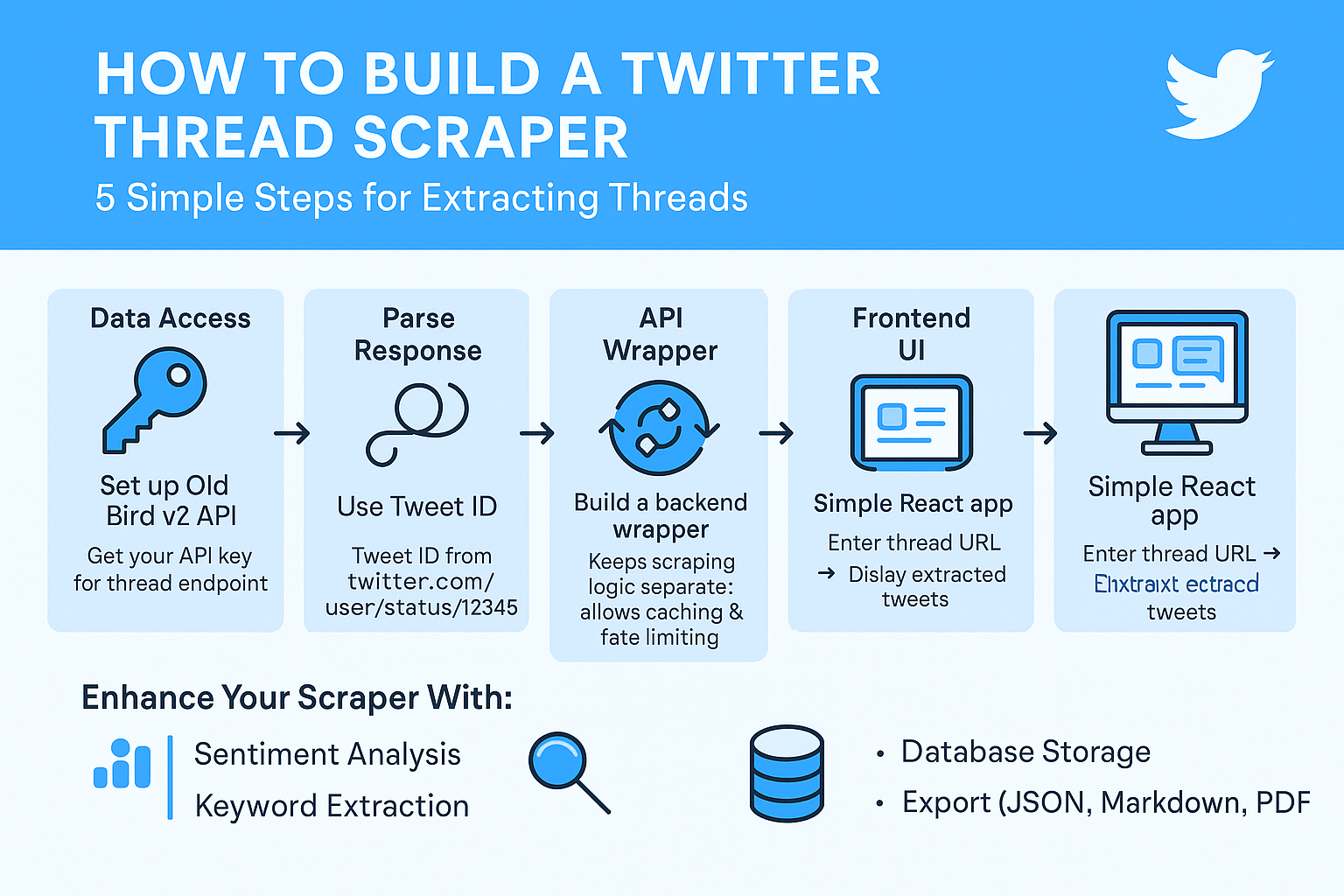
Here’s a step-by-step guide to building your own Twitter thread scraper using readily available tools.
Why Twitter Thread Scraping Matters
Twitter threads contain some of the platform’s most valuable content—detailed explanations, tutorials, storytelling, and analysis that often gets buried in the platform’s fast-moving timeline. Having the ability to extract, preserve, and analyze these threads opens up possibilities for:
- Content research and competitive analysis
- Academic research on social media discourse
- Building thread reader applications
- Creating content summaries and insights
- Preserving important discussions
Step 1: Set Up Twitter Data Access with Old Bird v2
The foundation of any Twitter scraping operation is reliable data access. Old Bird v2 on RapidAPI provides an alternative to Twitter’s official API with more flexible access patterns.
Why Old Bird v2?
- No complex authentication requirements
- More generous rate limits than official Twitter API
- Designed specifically for data extraction use cases
- Handles Twitter’s anti-bot measures automatically
Visit the Old Bird v2 RapidAPI page to get started. You’ll need to subscribe to a plan (they typically offer free tiers for testing) and obtain your API key.
The service provides various endpoints, but for thread scraping, you’ll primarily use their conversation/thread endpoint.
Step 2: Understanding the Thread Extraction Endpoint
The key to extracting Twitter threads lies in understanding how Twitter structures conversation data. When you view a thread on Twitter, you’re actually looking at a conversation view that includes the original tweet and all its replies in chronological order.
The endpoint you need: The threaded conversation endpoint Required parameter: Tweet ID (found in any Twitter URL)
For example, in the URL https://twitter.com/user/status/1234567890, the tweet ID is 1234567890.
How it works:
- Pass the tweet ID of any tweet in the thread (usually the first one)
- The API returns the complete conversation structure
- Filter and extract the tweets that belong to the original thread author
Step 3: Parsing Twitter’s Complex Response Structure
This is where most developers get stuck. Twitter’s API responses are notoriously complex, with deeply nested JSON structures that can be intimidating to navigate.
The Challenge: Twitter’s response includes not just the tweets you want, but also:
- Promoted tweets and ads
- Recommended follows
- Various metadata objects
- UI injection points
- Analytics data
The Solution: Here’s the key code pattern for extracting the actual tweets from the response:
const timelineAddEntries =
http://response.data.data.threaded_conversation_with_injections_v2.instructions.find(
(instruction) => instruction.type === "TimelineAddEntries"
);
const entries = timelineAddEntries.entries;
const timelineModule = entries.find(
(entry) => entry.content.entryType === "TimelineTimelineModule"
);
const items = timelineModule.content.items;
const tweets = http://items.map(
(item) => item.item.itemContent.tweet_results.result
);
const tweetsFormatted = http://tweets.map((tweet) => ({
id: http://tweet.rest_id,
text: tweet?.legacy?.full_text,
media_urls: tweet?.legacy?.entities?.media?.map(
(media) => media?.media_url_https
),
}));
What this code does:
- Finds the
TimelineAddEntriesinstruction in the response - Extracts entries that contain actual tweet data
- Filters out non-tweet content (ads, suggestions, etc.)
- Returns only tweets from the original thread author
Step 4: Creating an API Wrapper Service
Rather than building the scraping logic directly into your application, it’s better to create a separate API service. This approach provides:
- Separation of concerns: Keep scraping logic separate from UI
- Reusability: Use the same API for multiple applications
- Rate limiting: Implement proper request management
- Caching: Store frequently requested threads
Step 5: Building the Frontend with AI Code Generation
Modern AI coding assistants can dramatically speed up frontend development. Instead of writing boilerplate React code from scratch, you can describe what you want and get a working application.
Example prompt for AI assistant: “I need a very simple app, written in Vite+React, where a user enters a Twitter thread URL, clicks a button to extract the thread, and sees all the tweets displayed in a clean, readable format. Include loading states and error handling.”
What you’ll get:
- Complete Vite+React setup
- Form handling for URL input
- API integration with your backend
- Loading and error states
- Clean UI for displaying thread content
Alternative Social Media Scraping
The techniques described here extend beyond Twitter. Many social platforms have similar patterns for extracting threaded content:
- LinkedIn post comments and discussions
- Reddit comment threads
- Facebook post comments
- Instagram comment threads
Services like Scrape Creators offer APIs for multiple social platforms. Try your first 100 requests for free.

