

Twitter scraping legality hinges on public versus private data—login walls change both risk and what courts have allowed.
X tightened public timelines. Workarounds exist, but terms-of-service and CFAA exposure differ sharply by method.
In this guide, you’ll learn:
- The public vs private golden rule
- How X changed access in recent years
- Workarounds and their limits
- Login scraping risks
Use the sections below as your playbook.
The Golden Rule: Public vs. Private Data
Here’s the bottom line that every developer needs to understand: anything in front of the login wall is legal and fair game.
This principle was solidified last year when Meta dropped its high-profile lawsuit against BrightData. Meta was furious about the scraping, but they couldn’t prove that BrightData was accessing data behind login walls, and that made all the difference legally.

The problem?
All the really valuable data such as the user’s latest tweets, comprehensive search results, real-time feeds, now sits behind Twitter’s login wall. This represents a fundamental shift in how Twitter operates compared to its pre-Elon era.
How Twitter Changed the Game
Before Elon Musk’s acquisition, Twitter was much more open. Search results were publicly accessible, and you could scrape chronological tweets without authentication.
Those days are long gone.
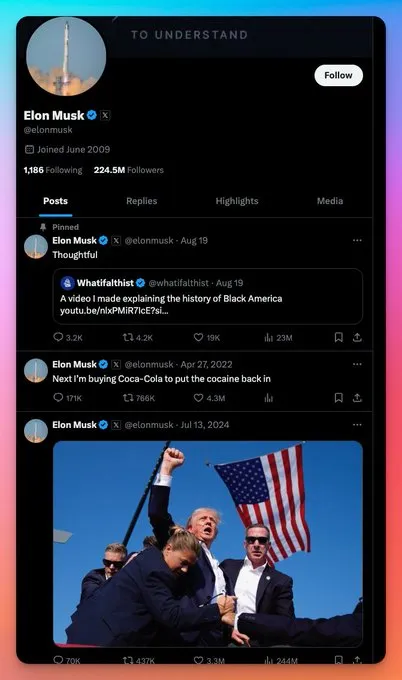
Now, if you visit someone’s Twitter profile in an incognito browser, you’ll discover you can only access their top 100 tweets. Everything else requires logging in.
This change has dramatically reduced what’s legally scrapable from Twitter. The platform has essentially moved most of its valuable content behind a paywall, making legitimate scraping much more challenging.
Creative Workarounds (With Limitations)
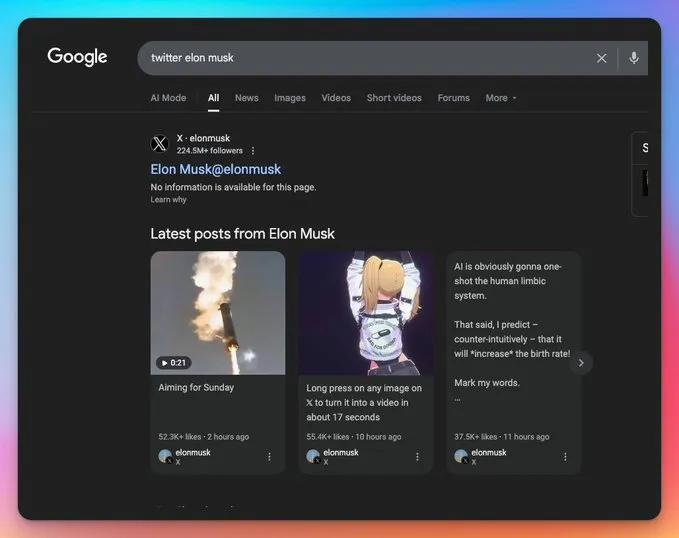
Some developers have found interesting ways to work around these restrictions. One clever hack involves using Google search to retrieve a user’s last 10 tweets. You can search for something like “twitter username” and Google will often return recent posts in the results. However, this method is finicky and doesn’t work consistently. For unknown reasons, it fails for certain users entirely.
While creative, these workarounds highlight the lengths developers must go to access what was once freely available public data.
The Risky Business of Login-Based Scraping
Despite the legal restrictions, Twitter scrapers continue to proliferate. The demand for Twitter data is simply too high for developers to ignore completely.
Third-party services offering Twitter scraping APIs have popped up on platforms like RapidAPI, often at incredibly attractive price points. However, the story of SocialData.tools serves as a cautionary tale.
Created by my friend Brian, the service gained popularity among developers seeking Twitter data. Twitter cracked down hard, not only shutting down the service but reportedly nuking Ships’ personal Twitter profile and forcing him to eliminate most of his API endpoints.
This aggressive enforcement demonstrates that while these services exist, they operate in legally questionable territory. Any scraping that occurs behind the login wall violates Twitter’s terms of service and potentially breaks the law.

Your Legal Options in 2025
So what can developers do if they need Twitter data while staying above board?
Option 1: Use Twitter’s Official API The safest route is Twitter’s official API. While it comes with rate limits and costs, it provides legitimate access to Twitter data with proper authorization.
Option 2: Stick to Public Data Only If you must scrape, limit yourself strictly to publicly accessible content that doesn’t require authentication. Remember, this severely limits what you can access. Use Scrape Creators for this.
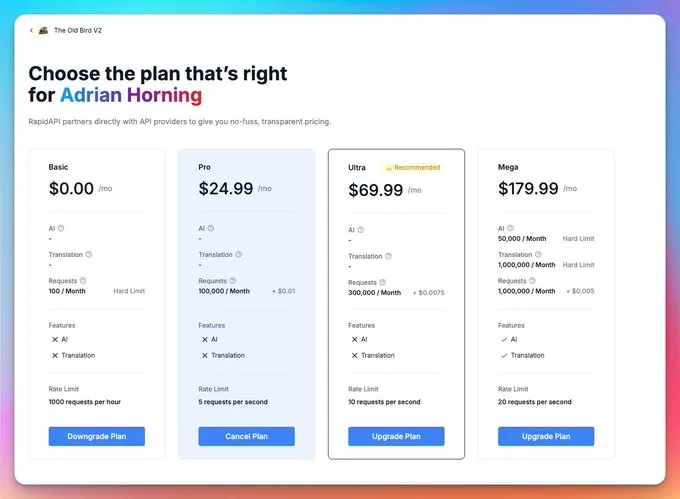
Option 3: Alternative Services Use an API on Rapid API called Old Bird V2. It has very generous pricing plans, but does scrape behind the login. But has been around for years.
The Bottom Line
The landscape of Twitter scraping in 2025 is clear: respect the login wall.
While the temptation to use unauthorized scrapers is understandable given the attractive pricing and extensive data access they offer, the legal and professional risks simply aren’t worth it.
The recent crackdowns show that Twitter is serious about protecting its data, and developers who cross the line face real consequences.
For sustainable, long-term projects, investing in official APIs or building solutions around truly public data remains the only viable path forward.

